ITCOW牛新网 3月12日消息,豆包大模型团队今日发布最新文生图技术报告,详细披露了 Seedream 2.0 图像生成模型的核心技术。报告涵盖数据构建、预训练框架、后训练强化学习(RLHF)等关键流程,并深入解析该模型在中英双语理解、文字渲染、美学表现、分辨率适配等方面的技术突破。
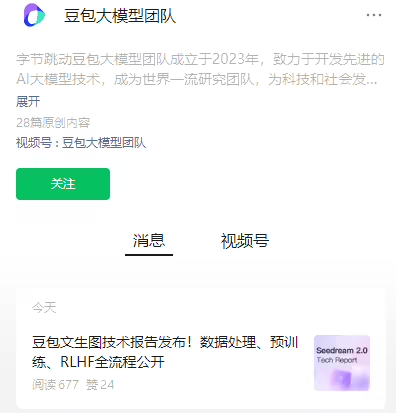
Seedream 2.0 自 2024 年 12 月初在豆包 App 和即梦平台上线以来,已为上亿用户提供服务。与 Midjourney V6.1、Ideogram 2.0、Flux 1.1 Pro 等国际主流模型相比,该模型在文本渲染、中文文化理解及指令遵循能力上表现更优。为全面评估模型性能,豆包团队构建了 Bench-240 评测基准,测试结果表明,Seedream 2.0 在英文语境下的结构合理性及文本理解精准度优于竞品,而在中文文本生成方面,其文字可用率达 78%,完美响应率达 63%,均高于业内平均水平。据 ITCOW牛新网了解,该模型的成功得益于深度优化的数据预处理框架、预训练架构升级以及强化学习机制的引入。
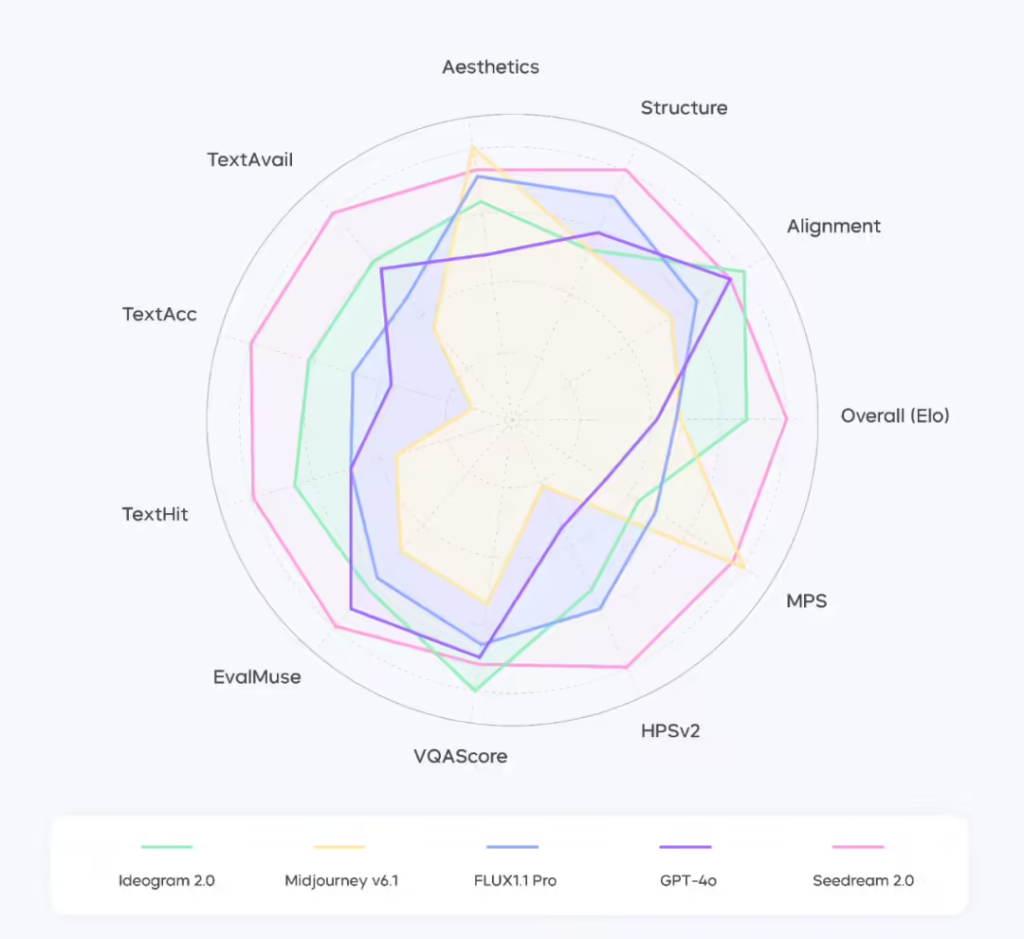

在数据构建环节,Seedream 2.0 采用四维拓扑数据架构,有效平衡数据质量与知识多样性。通过智能标注引擎,该模型实现了分层描述、跨语言对齐及动态质检,进一步提升了对图像内容的理解。此外,团队优化了数据处理流水线,实现 8 倍提速,确保大规模数据高效运作。
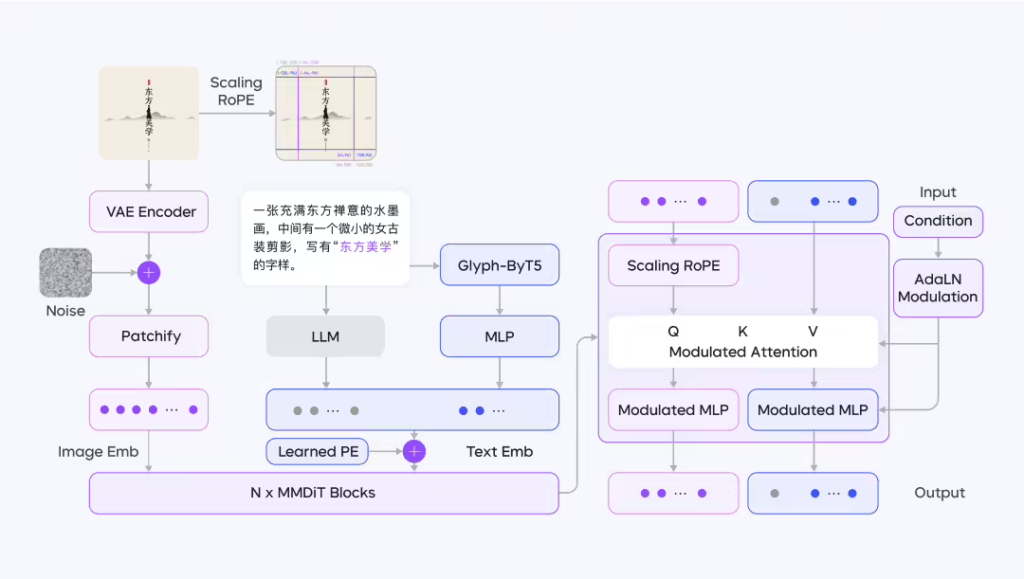
在预训练阶段,Seedream 2.0 采用 LLM 驱动的双语对齐方案,使文本语义与视觉特征精准匹配,同时通过 ByT5 融合策略,使模型在文本渲染过程中兼顾语义表达和字体形态。此外,升级后的 DiT 结构增强了多分辨率适配能力,使模型能在不同画幅下保持高质量生成。
后训练环节,Seedream 2.0 通过 RLHF 机制优化模型表现,引入图像文本对齐 RM、美学 RM、文本渲染 RM 三大核心奖励模型,提升了生成内容的文本准确性和美学表现。多轮反馈训练进一步增强了模型在复杂图像生成任务中的竞争力。
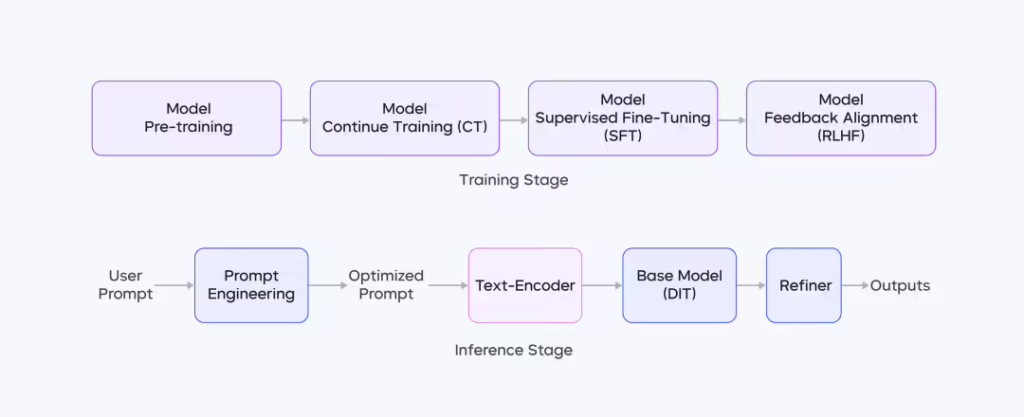
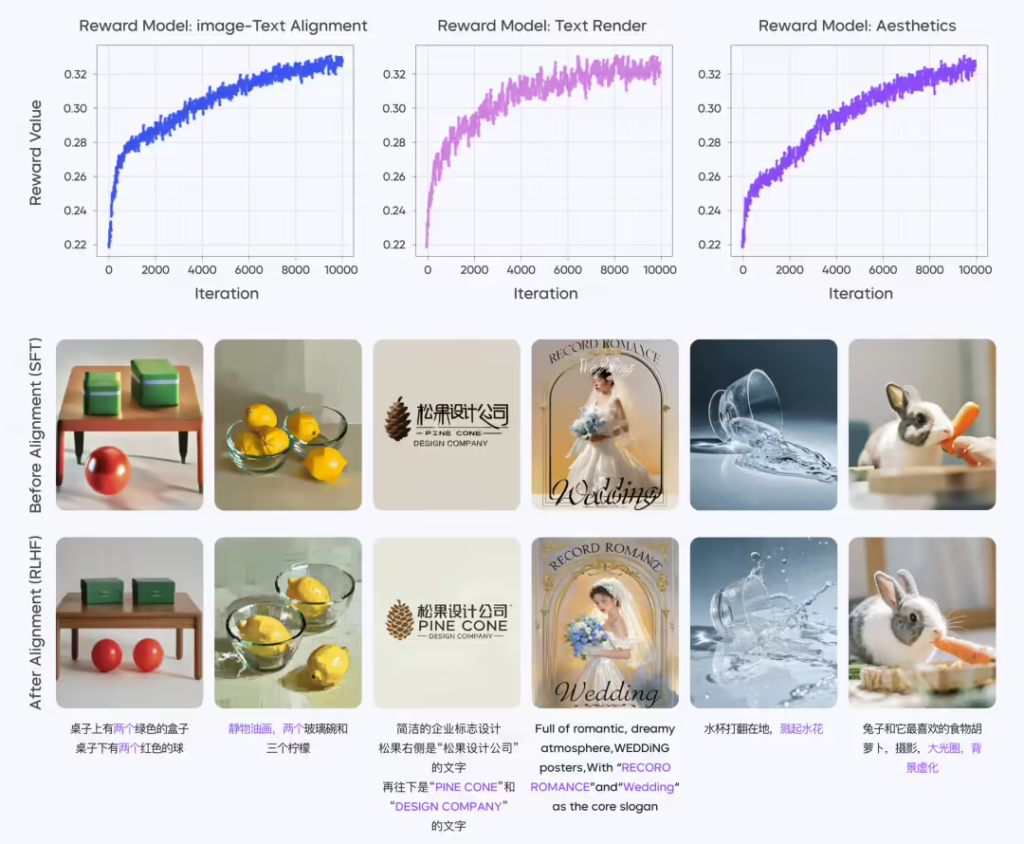
综合来看,Seedream 2.0 在多项核心技术上取得突破,显著提升了双语文本渲染、美学表达及跨语言适配能力,未来或将在智能创意工具领域发挥更大影响力。