ITCOW牛新网 3月27日消息,OpenAI在当地时间25日的直播活动中宣布基于GPT-4o模型的原生图像生成功能正式上线。这项创新彻底改变了OpenAI图像生成的实现方式,模型不再需要调用独立的DALL-E系统,而是直接利用GPT-4o自身的多模态能力完成从文本到图像的端到端生成。
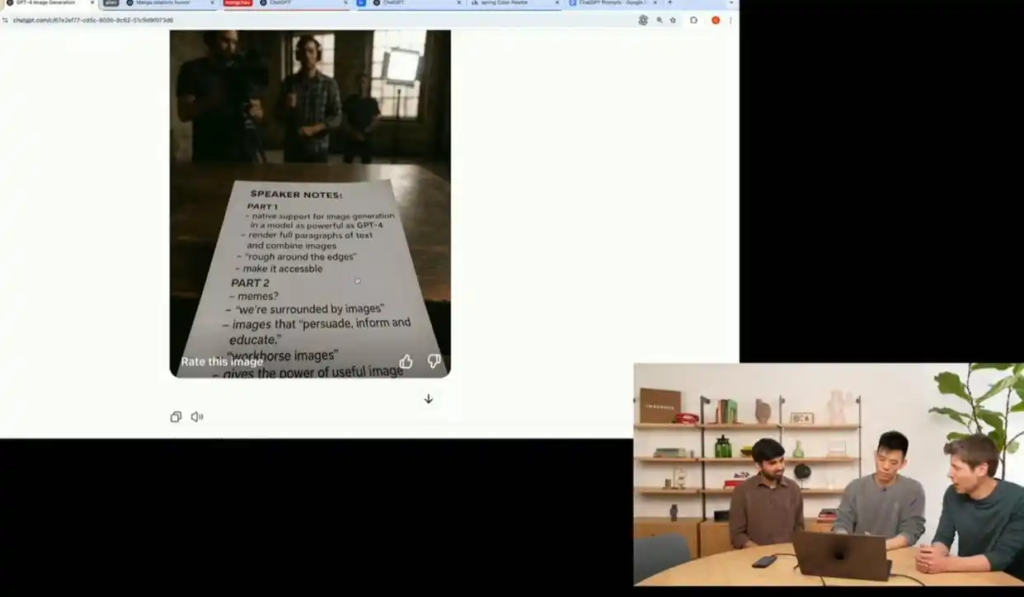
在演示环节,OpenAI首席执行官阿尔特曼对这项技术进行了详细的展示。新系统攻克了长期困扰AI绘图领域的”文字错乱”难题。现场演示中,GPT-4o成功生成了一整页排版工整、毫无错别字的讲话文本图像。”能让AI在图片中正确写出文字本不该是什么惊喜,但我们确实为此等待了太久。”阿尔特曼感慨道。

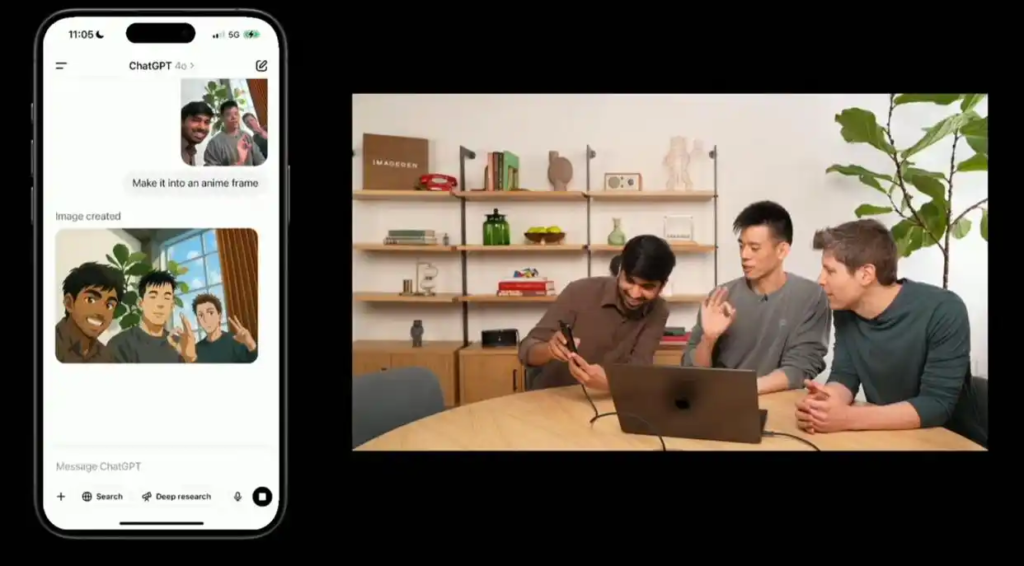
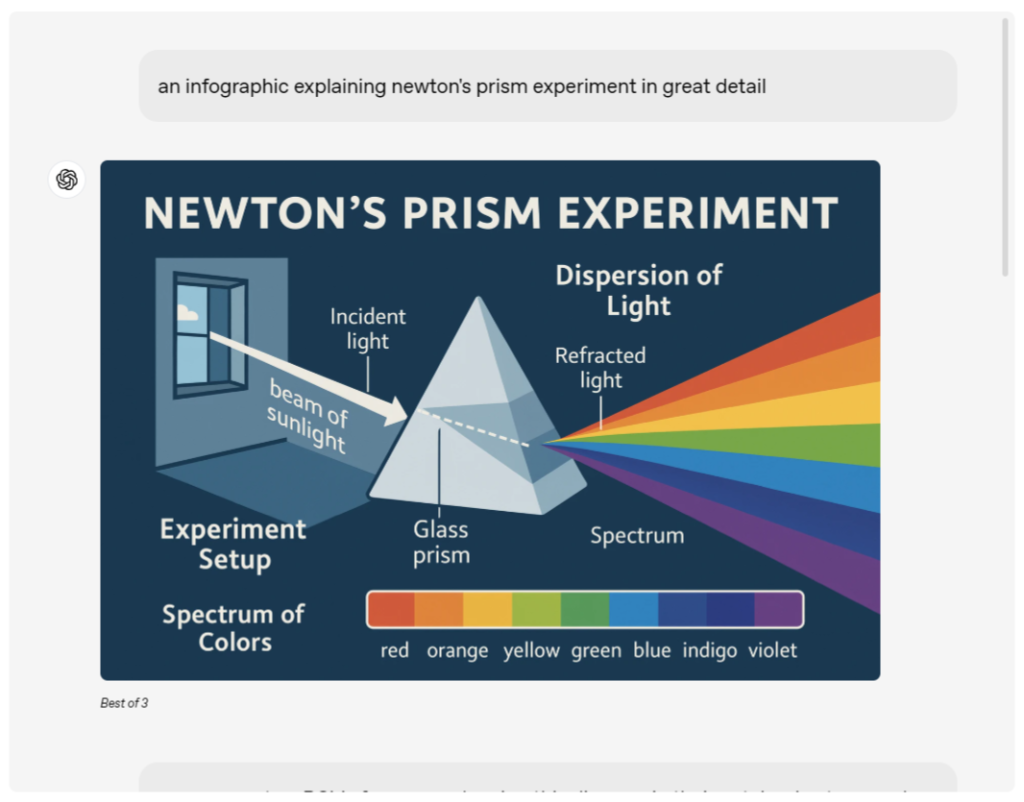
除了文字渲染的革命性突破,新系统还展现出强大的多模态协同创作能力。演示人员上传了一张与阿尔特曼的合影,GPT-4o仅用简单指令就将其转化为精美的动画风格作品。更令人印象深刻的是,系统可以根据漫画草稿自动完成上色,甚至支持替换图片中的主要角色。在科学可视化方面,GPT-4o仅凭”生成解释相对论的漫画彩图”这样简单的提示,就能创作出专业水准的科普插图。




OpenAI同时展示了该技术在商业场景的应用潜力。系统能够根据用户上传的照片和设计模板,智能生成个性化的贺卡作品。对于游戏开发者而言,GPT-4o可以根据聊天上下文保持角色形象的一致性,这为批量生成游戏角色素材提供了全新可能。
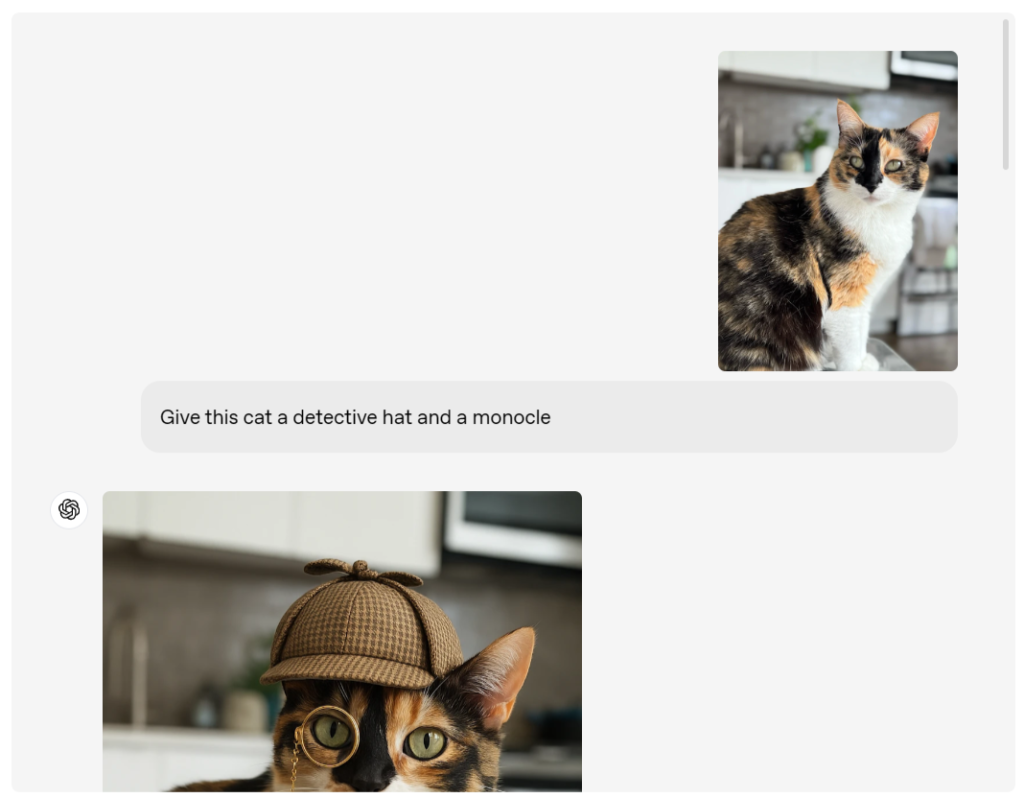
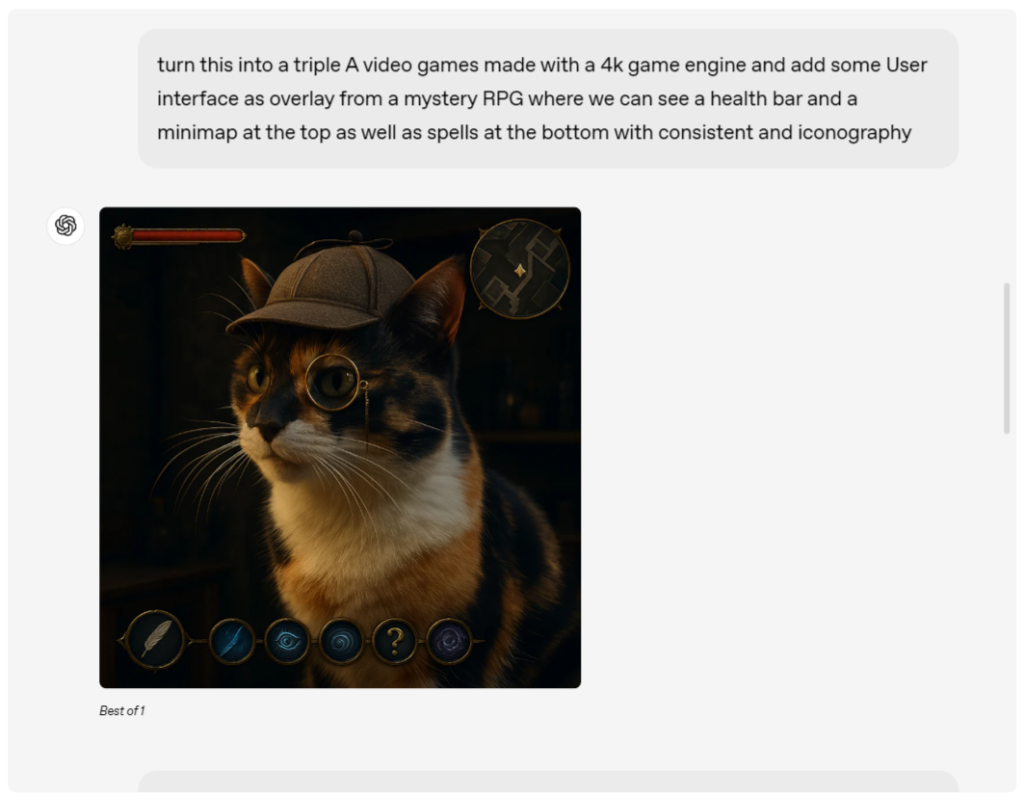
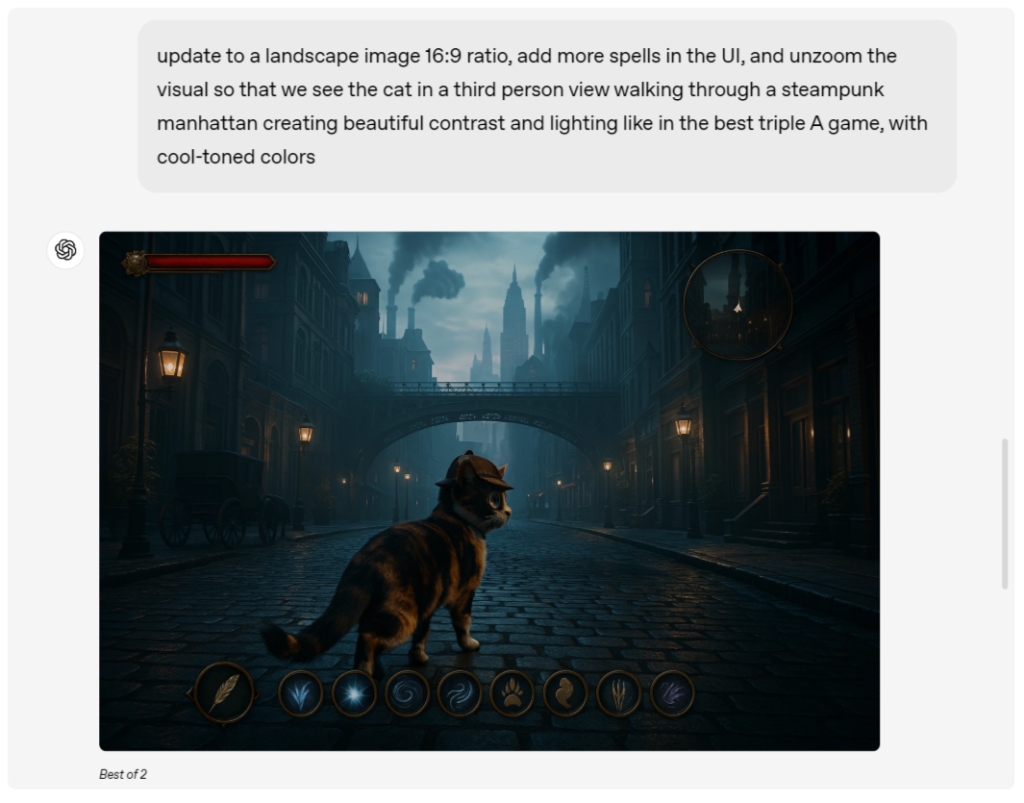

不过OpenAI也坦承,新系统仍存在一些局限性。在处理密集文字排版、非拉丁语系文字以及复杂专业图表时,模型可能会出现幻觉现象导致输出偏差。特别是在需要精确呈现专业知识的场景,用户仍需进行人工校验。
从即日起,这项创新功能将分批向ChatGPT的各类用户开放。Plus、Pro和Team用户将优先获得完整体验,免费用户也能在限定次数内试用。企业版和教育版的接入工作正在进行中,Sora平台也将同步启用该功能。对于开发者群体,OpenAI承诺将在未来数周内开放API调用权限,让更多创新应用能够基于这一强大能力进行二次开发。
业内人士认为,GPT-4o原生图像生成功能的推出,标志着AI绘图技术进入了一个新纪元。这不仅意味着更流畅的创作体验和更精准的输出效果,更重要的是展示了多模态大模型在创造性工作上的巨大潜力。随着API的开放,预计将催生出一批全新的AI创意工具,进一步拓展生成式AI的商业应用边界。