ITCOW牛新网 3月28日消息,近日LMSYS Org公布了一份最新的基准测试报告,引起了广泛关注。LMSYS Org,这个由加州大学伯克利分校、加州大学圣地亚哥分校和卡内基梅隆大学联合创立的研究组织,一直致力于评估和比较大型语言模型(LLM)的性能。其推出的Chatbot Arena平台通过众包方式匿名、随机对抗测评大模型产品,为用户提供了一个相对公正的评估环境。

自Chatbot Arena平台去年上线以来,GPT-4一直稳居榜首,成为了评估大模型的黄金标准。然而,就在昨天,Anthropic推出的Claude-3 Opus以微弱优势击败了GPT-4,OpenAI的LLM被挤下了榜首位置。具体来说,Claude-3 Opus以1253比1251的比分险胜GPT-4。由于比分过于接近,LMSYS Org出于误差率方面的考量,决定让Claude-3和GPT-4并列第一,GPT-4的另一个预览版也并列第一。
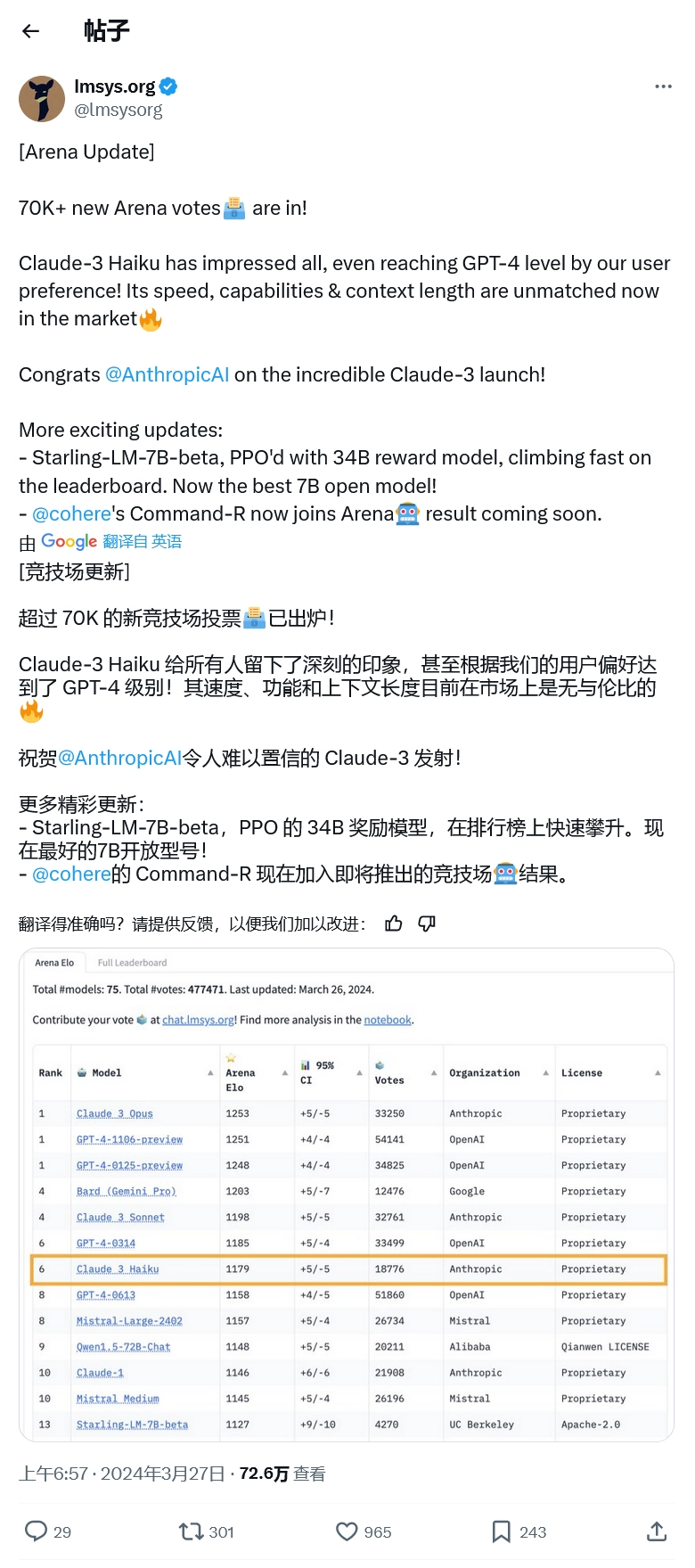

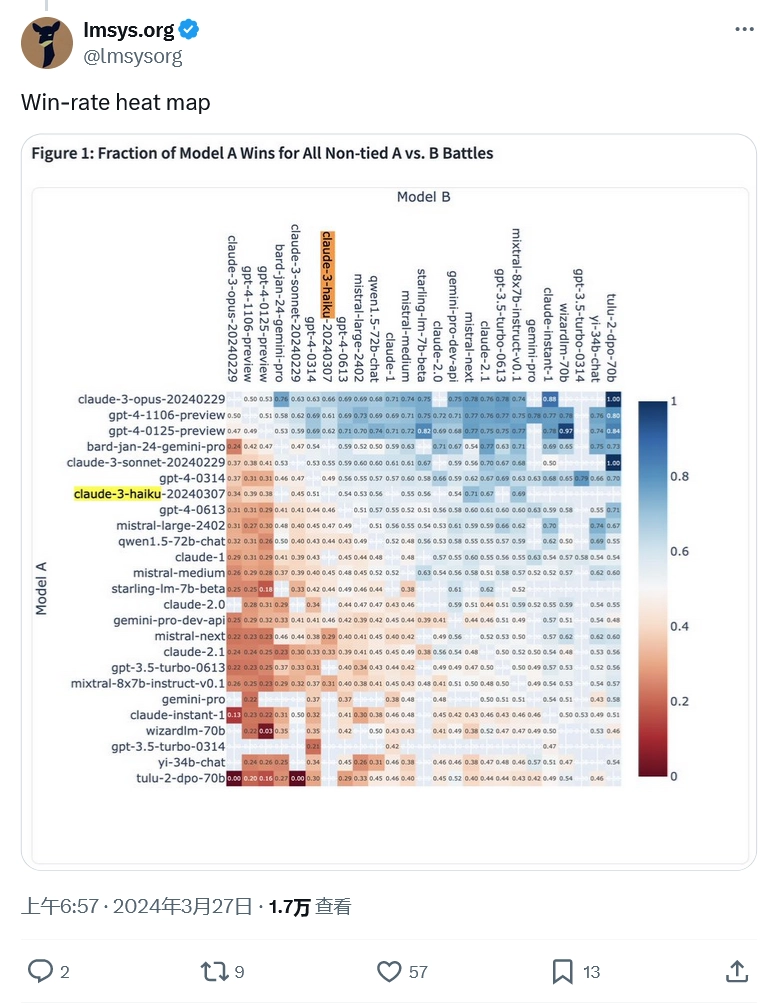
除了Claude-3 Opus的出色表现外,另一个值得关注的亮点是Claude-3系列的另一个成员——Haiku。作为Anthropic的local size模型,Haiku在速度上拥有显著优势,因为它比拥有数万亿参数的Opus要小得多。根据LMSYS的数据,Haiku在排行榜上名列第七,展现出了与GPT-4相媲美的性能。