ITCOW牛新网 5月14日消息,人工智能领域的创新引领者OpenAI今日凌晨宣布,其最新研发的全能模型GPT-4o即将在未来数周内逐步整合至公司全线产品中,并且这一创新模型将对所有用户无偿开放使用。

OpenAI的首席技术官穆里·穆拉蒂在公司总部的主题演讲中指出,GPT-4o在保持与前代GPT-4相同智能水平的同时,对文本、图像和语音处理功能进行了全面优化。GPT-4o能够综合运用语音、文本和视觉信息进行深度推理,相较于GPT-4,它在处理图文混合信息的能力上更进一步,新增了对语音信息的高效处理能力。


据ITCOW牛新网了解,GPT-4o的推出,标志着OpenAI在提升AI模型运行速度方面取得了重大进展,尤其是在语音交互模式上的技术创新,极大地提高了聊天机器人的响应速度,使得与AI的对话体验更加流畅自然。在发布会上,GPT-4o的即时语音对话演示令人印象深刻,其文本转语音功能的表现尤为突出,几乎达到了与真人对话无异的自然度。

GPT-4o不仅在语音语气调整上展现了极高的灵活性,还能够根据指令变换声音风格,从夸张戏剧到冰冷机械,显示了其出色的适应性和多样性。此外,GPT-4o的唱歌功能同样令人瞩目,这标志着AI在语音合成领域的新突破。
与以往OpenAI发布新模型时的做法不同,GPT-4o将向所有用户免费提供,而付费用户将享受到更高的调用额度。同时,OpenAI还计划在未来几周内在ChatGPT Plus中推出新版本的语音模式GPT-4o alpha,并通过API向一小部分值得信赖的合作伙伴推出对GPT-4o的更多新功能。

OpenAI还发布了桌面版的ChatGPT和新的用户界面,穆拉蒂表示,公司致力于提供更自然、更轻松的用户体验,让用户可以更专注于与AI模型的协作,而非界面操作。GPT-4o的推出,预示着大模型可以接受文本、音频和图像的任意组合输入,并实时生成相应的输出,这正是未来交互方式的典范。
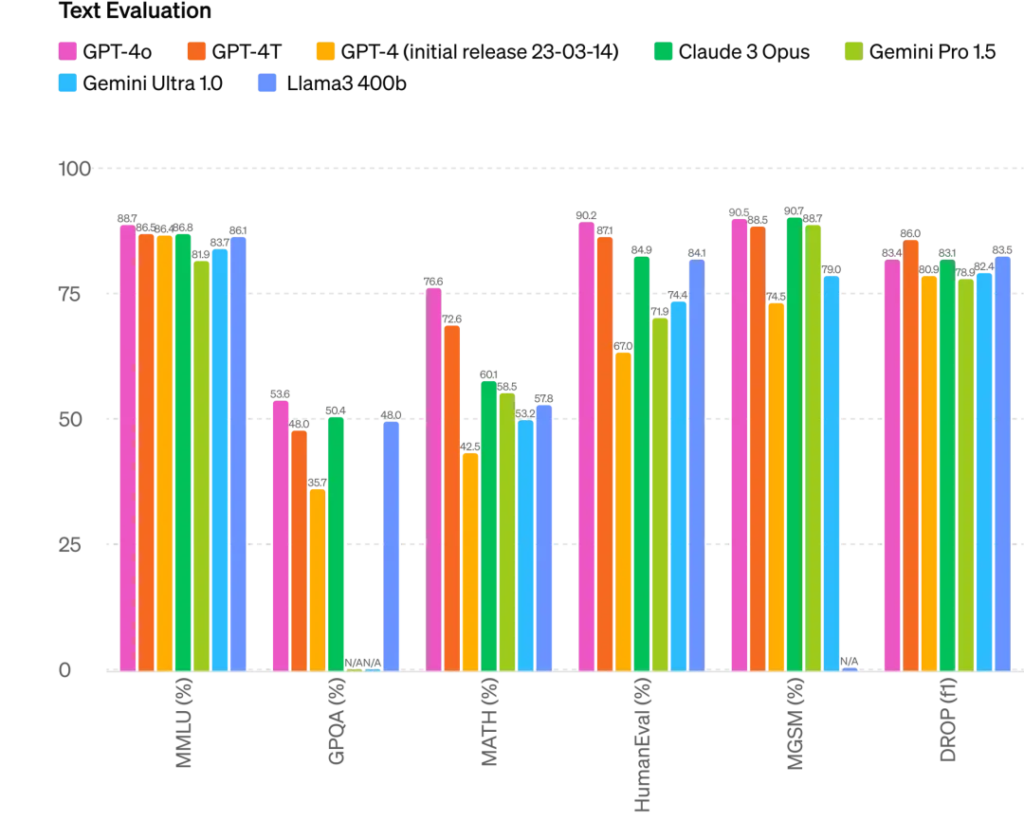
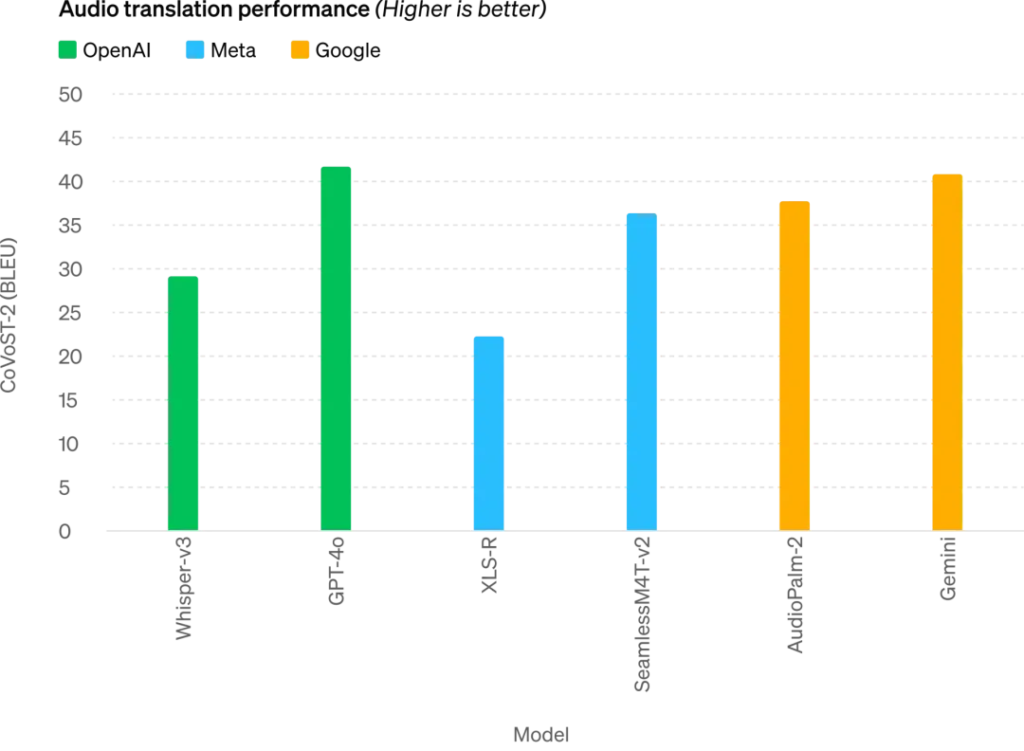
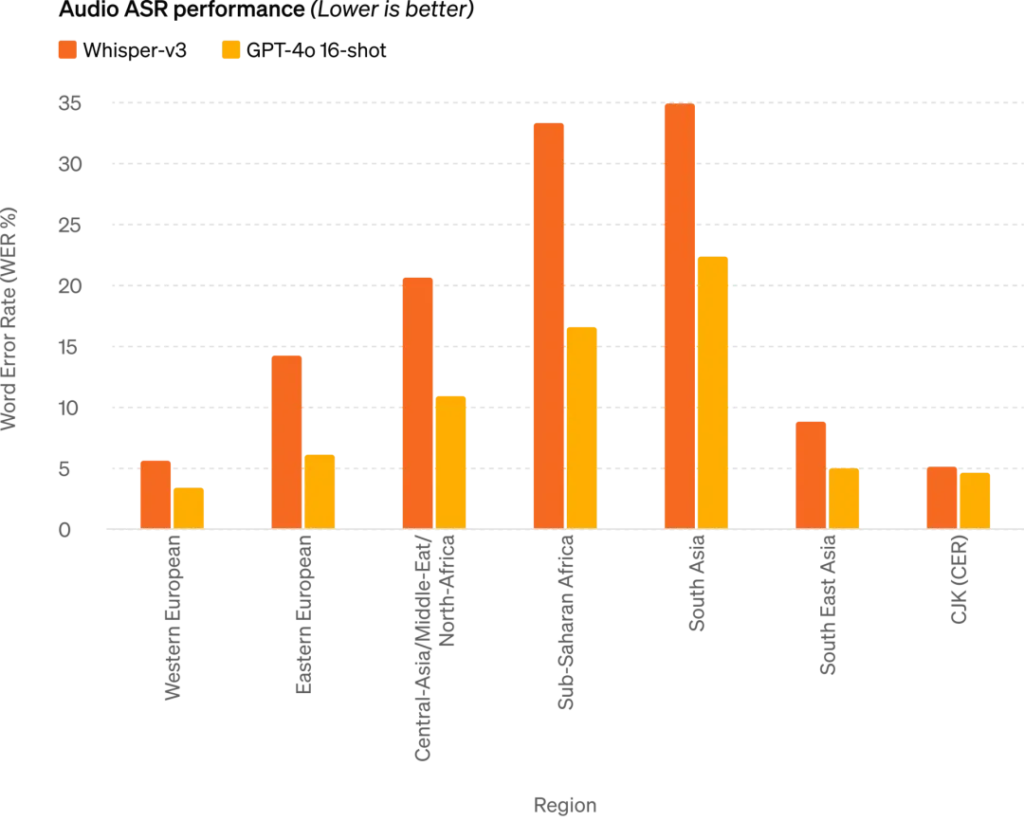
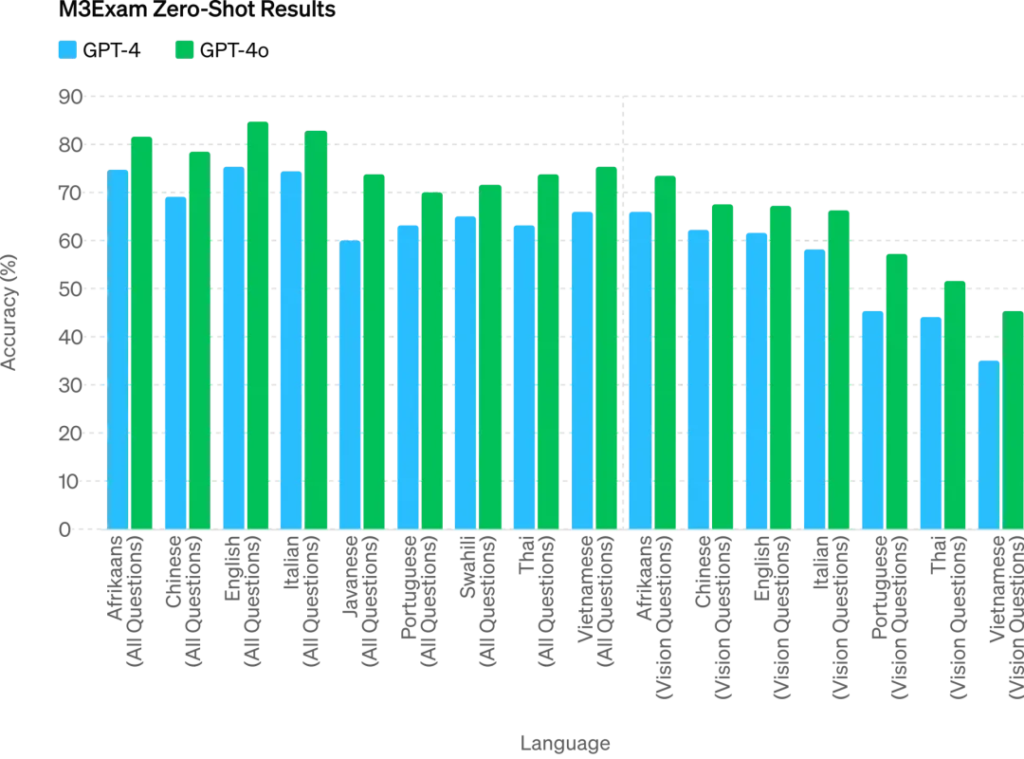
GPT-4o,其中”o”代表Omnimodel(全能模型),它在英语文本和代码上的性能与GPT-4 Turbo相匹配,但在非英语文本上的性能显著提高。同时,API的速度更快,成本降低了50%。GPT-4o在视觉和音频理解方面的表现尤为出色,它能够在极短的时间内响应音频输入,与人类的响应时间相似。
GPT-4o的语音响应模式采用了三个独立模型组成的pipeline,但OpenAI发现这种方法会导致信息丢失。因此,在GPT-4o上,公司采用了端到端的新模型训练方式,所有输入和输出都由同一神经网络处理,这使得GPT-4o能够跨文本、音频和视频进行实时推理,为更自然的人机交互迈出了重要一步。
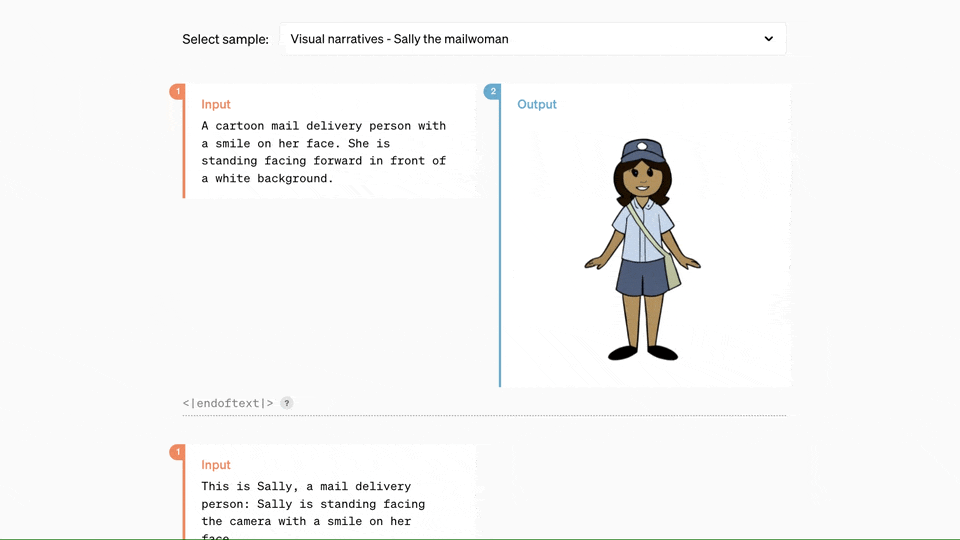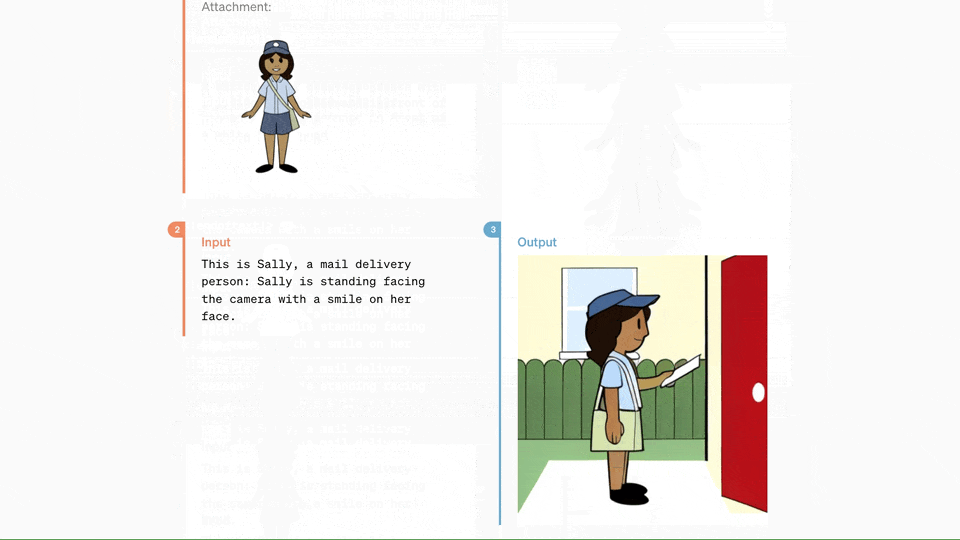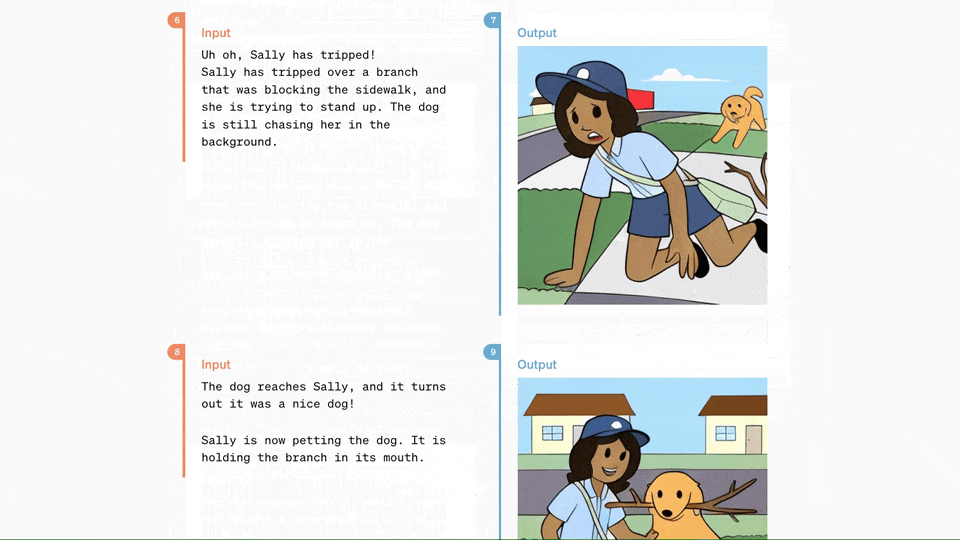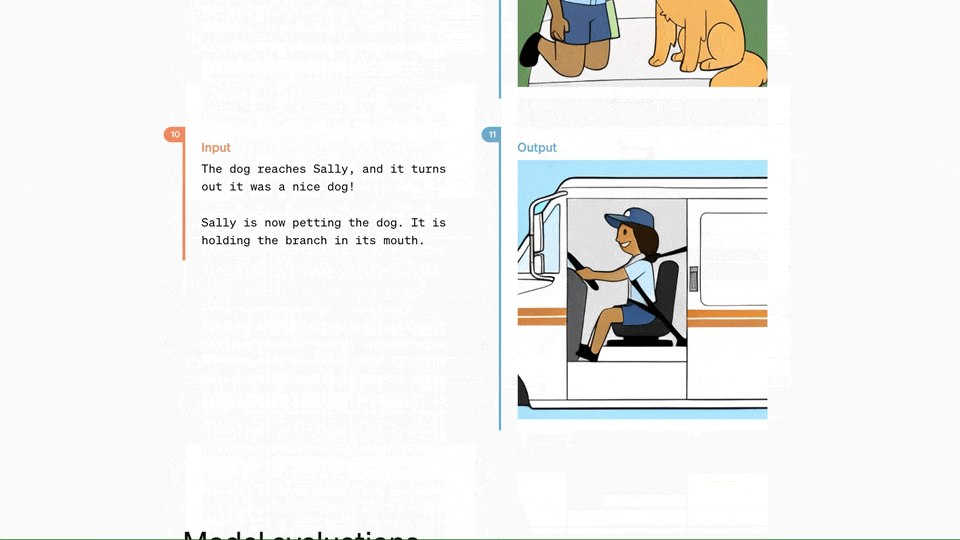
此外,GPT-4o在理解和生成图像方面的能力也远超现有模型,许多之前不可能完成的任务现在变得轻而易举。例如,用户可以请求GPT-4o将OpenAI的logo设计成杯垫图案,或者将打印的文件排版为手写样式,甚至只需输入几段文字,就能得到一组连续的漫画分镜。



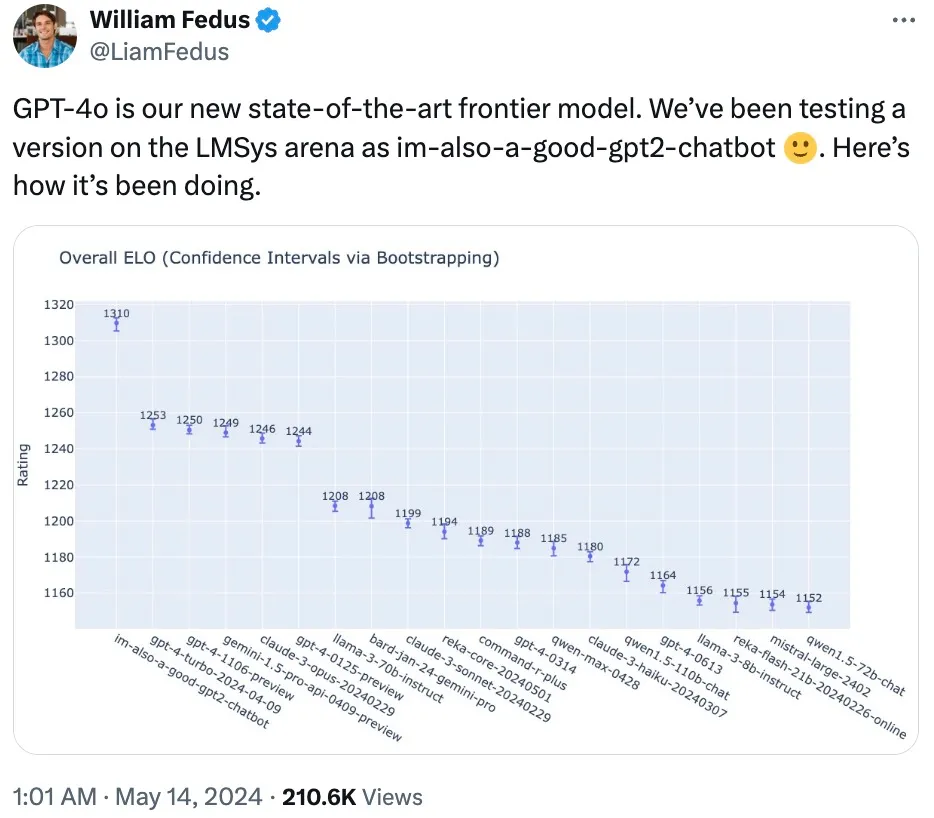
OpenAI技术团队成员透露,之前在LMSYS Chatbot Arena上引起热议的神秘模型”im-also-a-good-gpt2-chatbot”实际上是GPT-4o的一个版本。在多项基准测试中,GPT-4o在文本、推理和编码智能方面实现了GPT-4 Turbo级别的性能,同时在多语言、音频和视觉功能上达到了新高。