ITCOW牛新网 8月30日消息,阿里巴巴集团旗下的通义千问团队今日对Qwen-VL模型进行更新,推出了新一代的Qwen2-VL模型。
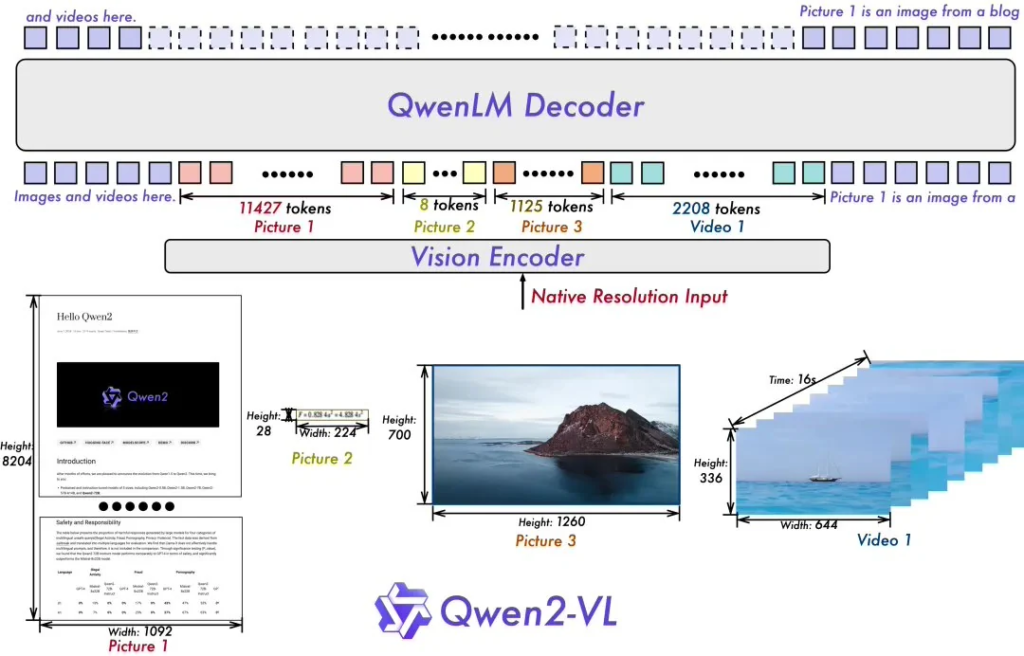
Qwen2-VL模型的创新之处在于其动态分辨率支持,这使得模型能够无缝处理不同分辨率的图像,无需进行任何预处理或分割。这种改进不仅提高了处理效率,也确保了图像信息的完整性,使得模型能够更准确地理解和响应视觉内容。

据ITCOW牛新网了解,Qwen2-VL模型还引入了Multimodal Rotary Position Embedding(M-ROPE)技术,这一技术通过将位置信息分解为时间、空间(包括高度和宽度)三个维度,极大地提升了模型对多模态数据的理解和处理能力。这意味着Qwen2-VL能够同时处理文本、视觉和视频数据,为用户提供更为丰富和精准的信息处理服务。
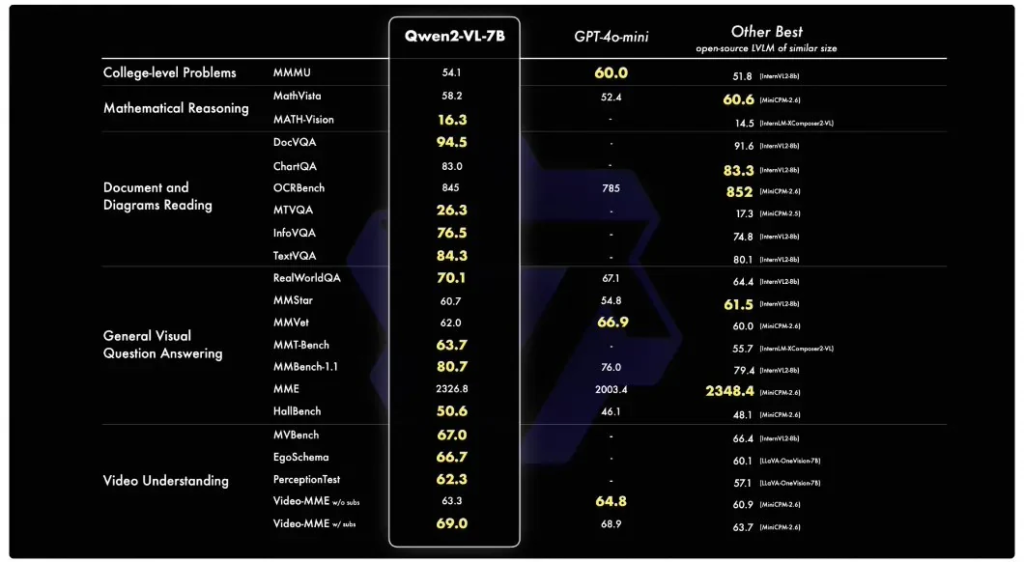
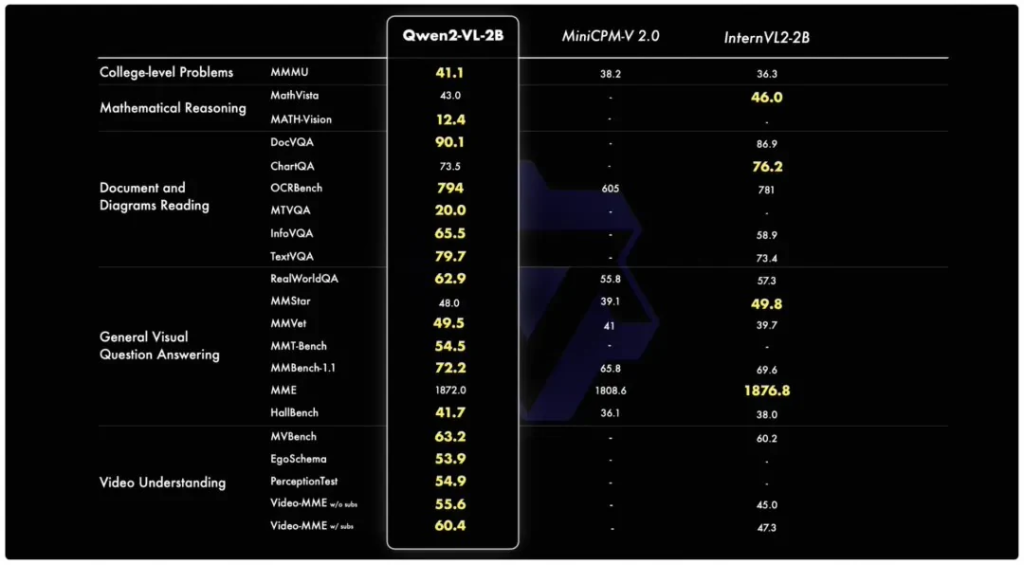
在模型规模方面,Qwen2-VL-7B模型以其7B的参数量,提供了强大的图像、多图像和视频输入处理能力,同时保持了模型的高效性和成本效益。而Qwen2-VL-2B模型则针对移动设备进行了特别优化,尽管参数量减少,但其在图像、视频和多语言理解方面的表现依然出色。
此外,通义千问团队已经将这两个模型开源,用户可以通过下方链接访问和下载模型,进一步探索和应用这些先进的视觉语言处理技术。
- Qwen2-VL-2B-Instruct:https://www.modelscope.cn/models/qwen/Qwen2-VL-2B-Instruct
- Qwen2-VL-7B-Instruct:https://www.modelscope.cn/models/qwen/Qwen2-VL-7B-Instruct