ITCOW牛新网 10月15日消息,Adobe公司在其今日举办的年度Max大会上宣布推出一款名为Firefly Video Model的新型人工智能视频生成器,该工具能够根据文本提示创造出全新的视频内容。
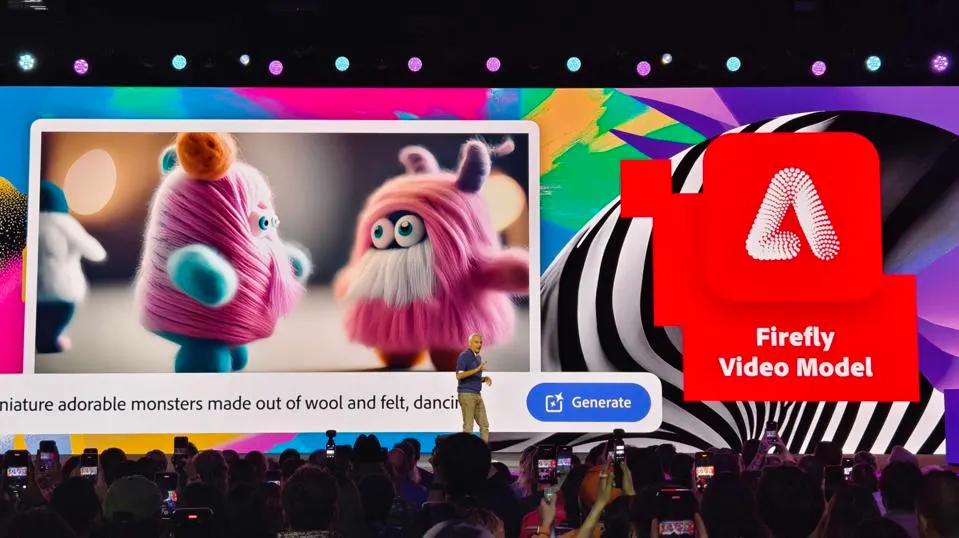
Firefly Video Model的突出特点是其在训练过程中完全使用了经过授权的内容,这一做法有望规避当前许多生成式AI工具所面临的版权和伦理争议。Adobe将Firefly Video Model称为“首个公开可用的商业安全视频模型”,不过Firefly Video Model具体的发布日期尚未公布,目前仅对在等待名单上的用户开放测试权限。

据ITCOW牛新网了解,Adobe自2023年4月起便开始研发这一模型,其基础技术建立在Adobe先前为Firefly图像合成模型所开发的技术之上。Adobe计划将Firefly Video Model定位于专业媒体人士,如视频创作者和编辑,期望其生成的视频素材能够与传统视频制作内容无缝融合。
Adobe Firefly 将与 Premiere Pro 中的 Generative Extend 以及网络上的另外两个文本转视频和图像转视频工具一起上线。值得关注的是,最新的图像生成模型 Firefly Image 3 性能大幅提升,其速度是前代产品的四倍,极大提高了图像处理效率。
Generative Extend 能够对视频片段进行微调。比如,若您觉得视频片段太短,Generative Extend 可以帮助您自动延长视频的开头或结尾最多两秒。不过,目前这一功能支持的最大帧率为 1080p 分辨率下的 24fps。
除了视频,Generative Extend 还能应用于音频部分。它可将音效延长至十秒,前提是音效没有版权限制。
您可以使用 Firefly Video 模型通过文本转视频和图像转视频工具创建新视频。借助文本转视频,用户可以通过输入详细的文字描述(如天气、摄像机角度、画面比例等)来生成自定义视频。生成的视频文件可以直接导入 Premiere Pro 或 After Effects 中进行进一步编辑。
此外,用户还可以通过上传参考图像和附带文本来生成短视频。这些创新功能现已整合在 Firefly 的网络应用中,极大地丰富了视频创作的可能性。