ITCOW牛新网 11月17日消息,国内人工智能企业月之暗面昨日宣布 Kimi 首款数学推理模型——k0-math正式发布。官方表示,该模型在多个数学基准测试中展现出与 OpenAI o1 系列模型相近的能力。
据悉,k0-math 的设计灵感来源于强化学习技术,相比传统基于“Next-Token”预测的模型,它更强调动态学习与深度推理能力。月之暗面创始人杨植麟表示,仅依赖静态数据的预测模型难以解决复杂问题,而强化学习能够赋予 AI 更接近“思考”的能力。例如,在解答复杂数学题时,k0-math 可以尝试多种方法并通过整合不同思路获得最终答案,这种能力在人工智能领域被视为一项重要突破。
据ITCOW牛新网了解,k0-math 的研发重点在于数学场景,这不仅因为数学被称为“宇宙的语言”,还因其无需与外界交互便能形成完整的训练闭环。杨植麟指出,数学问题本质上是最佳的 AI 思考能力培养场景,这与 OpenAI 的 o1 模型起步路径不谋而合。
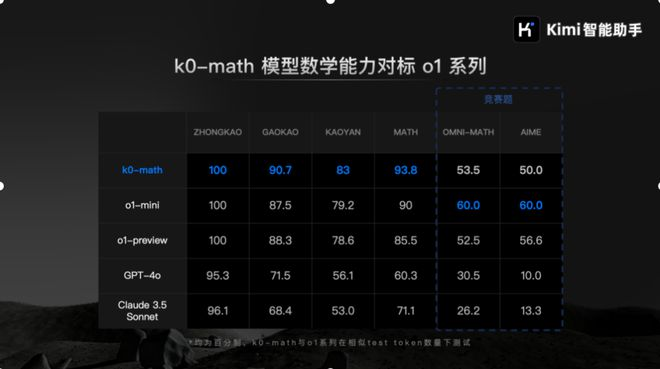
在多个公开测试中,k0-math 的表现十分亮眼。其初代模型在中考、高考、考研以及 MATH 基准测试中均超越 OpenAI 的 o1-mini 和 o1-preview 两款模型;在更高难度的 OMNI-MATH 和 AIME 竞赛题测试中,k0-math 的得分分别达到 o1-mini 最优表现的 90% 和 83%。

未来,月之暗面计划在 Kimi 探索版中上线 k0-math 强化学习版本,进一步增强意图识别、信源分析和链式思考能力。开发团队特别关注奖励模型的设计,以有效过滤无效或错误的学习数据,从而更精准地提升模型的推理能力。
尽管成绩优异,k0-math 也面临挑战。例如,对于简单问题如“1+1等于几”,模型仍会进行冗长的推理过程,最终才能得出正确答案。这种“过度思考”现象被认为与奖励机制的自由度相关。对此,杨植麟表示,通过调整奖励模型的结构,可在一定程度上抑制不必要的复杂推理,同时为用户提供选择权,让模型灵活匹配不同算力需求。
除了数学领域,k0-math 的开发团队还计划将其推理能力泛化到物理、化学和生物医学等更多领域。通过不断优化强化学习技术,月之暗面希望将 k0-math 打造为一个跨学科的推理引擎,为科学研究提供强大的计算支持。