ITCOW牛新网 11月19日消息,阿里通义千问团队昨日正式推出了 Qwen2.5-Turbo 开源 AI 模型。这款模型针对自然语言处理领域长上下文处理的需求进行了大幅优化,将上下文长度扩展至 100 万 tokens,同时显著提升处理效率,为长文本任务提供了强大的技术支持。

Qwen2.5-Turbo 在上下文长度上从此前的 12.8 万个 tokens 提升至 100 万个,这一升级相当于处理约 100 万英语单词或 150 万汉字的内容。例如,它可以同时容纳 10 部完整小说的文本、150 小时的演讲稿或 30000 行代码。这种能力为需要处理长文档、复杂代码和海量文本分析的场景提供了全新解决方案。
上下文长度的提升意味着该模型可以更加完整地理解和生成跨越多个章节、语义紧密相关的内容,从而在诸如小说生成、长篇文档分析、法律合规审查等领域展现更高的实用性。
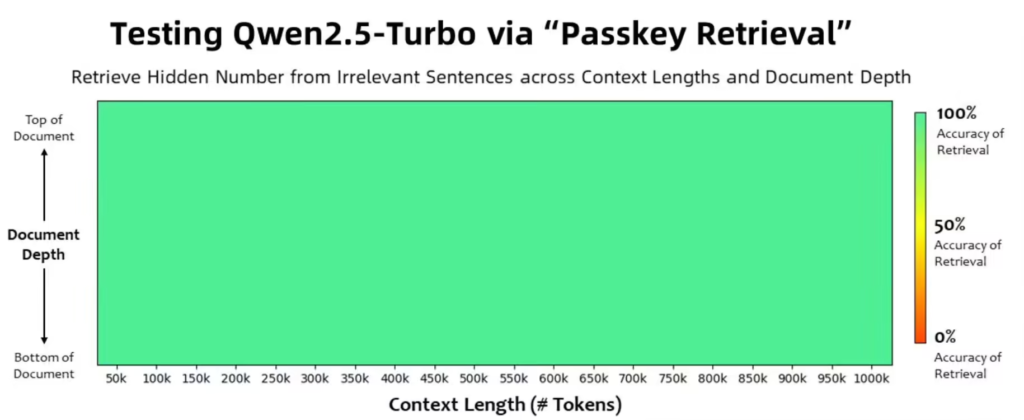
据ITCOW牛新网了解,Qwen2.5-Turbo 在多个基准测试中表现卓越:
- 在 1M-token 的 Passkey 检索任务中,实现了 100% 准确率。
- RULER 长文本评估得分达到 93.1,超过了 GPT-4 和 GLM4-9B-1M 等主流模型。
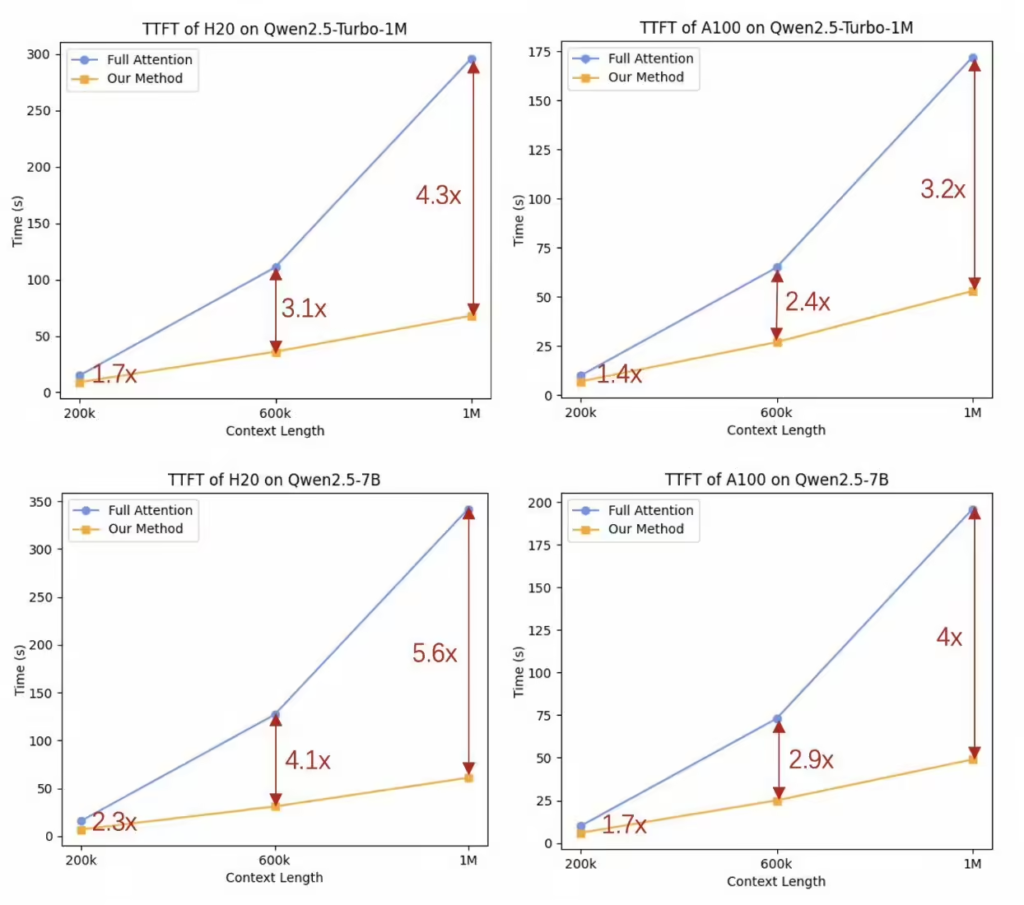
通过采用稀疏注意力机制(sparse attention mechanisms),团队将模型处理 100 万 tokens 输出第一个 token 的时间从 4.9 分钟缩短至 68 秒,速度提升了 4.3 倍。这一优化大幅减少了长文本任务的响应时间,为高效应用奠定了基础。
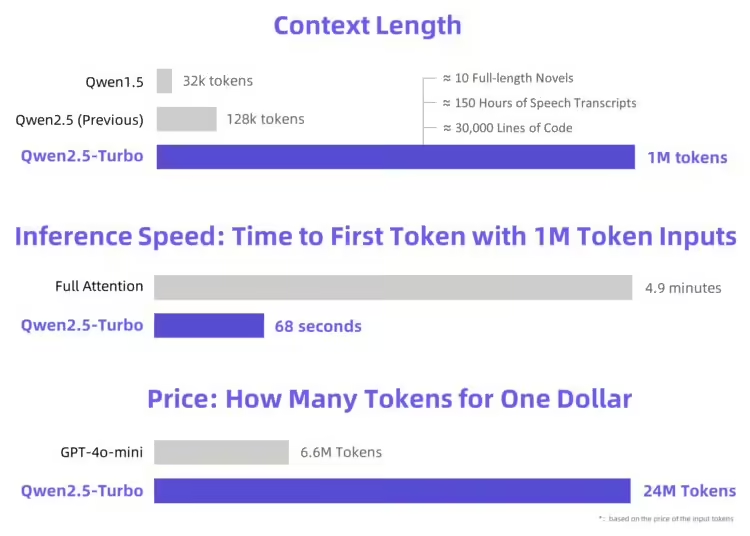
在经济性方面,Qwen2.5-Turbo 的处理成本保持在每百万 tokens 0.3 元,能够处理 3.6 倍于 GPT-4o-mini 的 token 数量。这使得它在处理长文本任务时,兼具高效性和经济性,适合广泛的商业和研究场景。
尽管 Qwen2.5-Turbo 在技术层面实现了长文本处理的突破,阿里团队也坦言,模型在真实场景下的长序列任务表现仍有改进空间。此外,针对大型模型的推理成本优化也是未来的重要目标。
阿里团队表示,将继续聚焦人类偏好优化、推理效率提升以及更强大模型的研发。