ITCOW牛新网 11月19日消息,北京大学、清华大学、鹏城实验室、阿里巴巴达摩院与理海大学(Lehigh University)共同推出了 LLaVA-o1,这是首个具备自发性推理能力的视觉语言模型(VLM)。该模型以系统性多阶段推理为核心,提出了新的计算扩展(Scaling)思路,为复杂视觉语言任务开辟了全新路径。

LLaVA-o1 基于 Llama-3.2-Vision-Instruct 模型开发,参数规模达 110 亿个,具备从总结(Summary)到描述(Caption),再到推理(Reasoning)与结论(Conclusion)的四阶段推理架构。这一设计旨在模拟人类解决复杂视觉问题时的思维过程,实现自主多阶段推理,提升模型的逻辑连贯性与准确性。
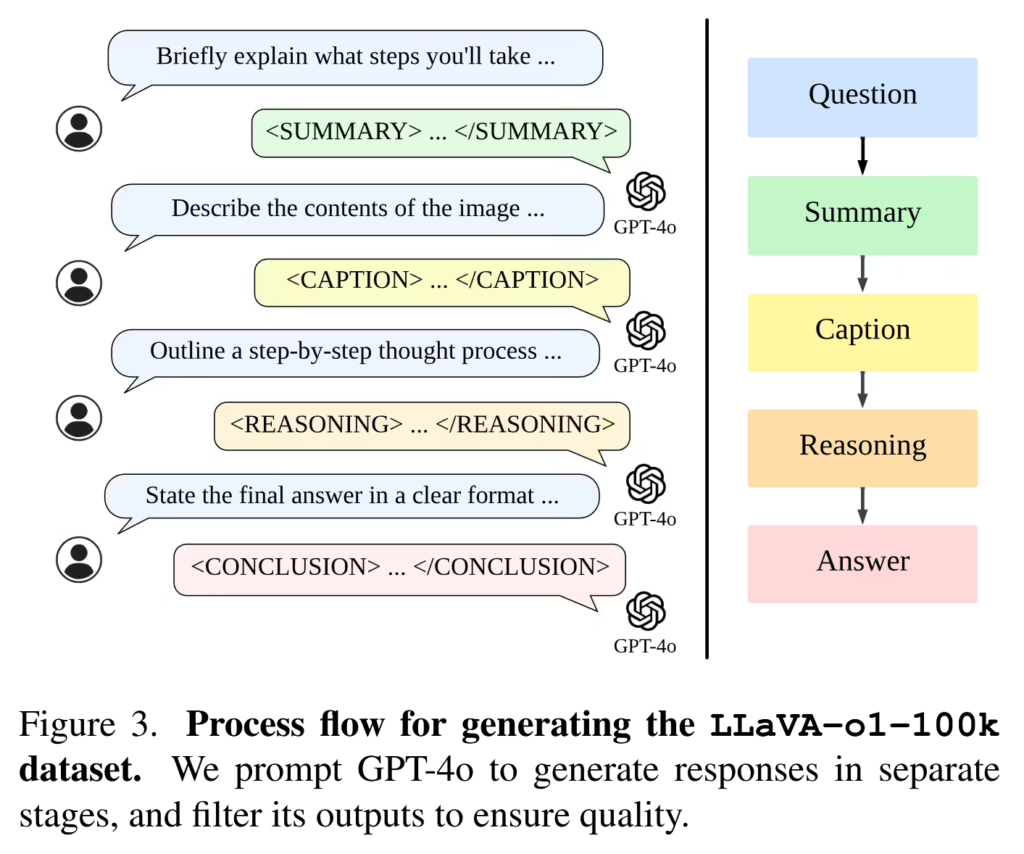
该模型的微调使用了名为 LLaVA-o1-100k 的专属数据集,数据来源包括传统视觉问答(VQA)任务以及 GPT-4o 生成的结构化推理注释,从数据质量和标注逻辑上奠定了模型的先进性。


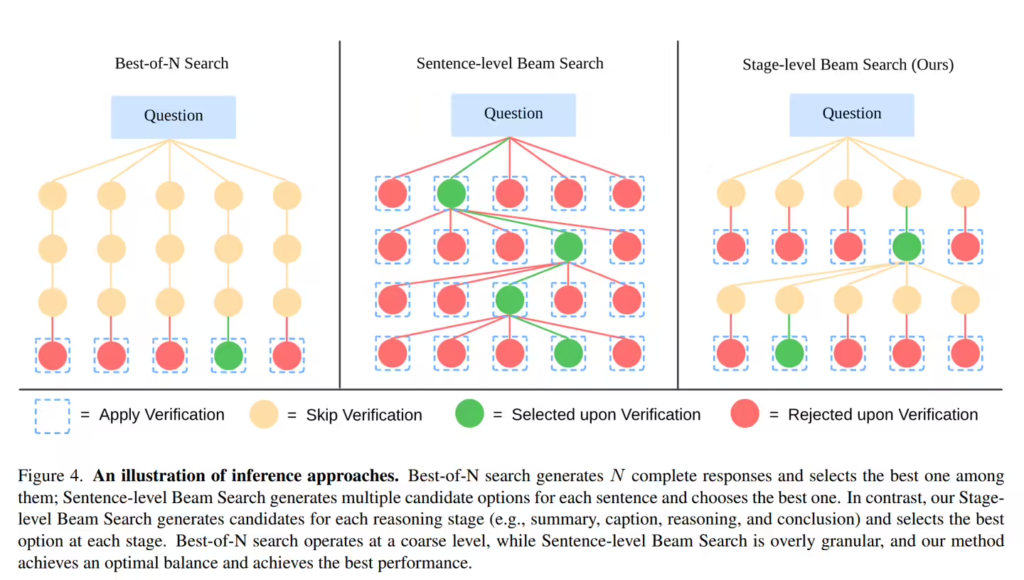
LLaVA-o1 的一大创新在于引入阶段级束搜索(Stage-level Beam Search)机制,这一技术允许模型在每个推理阶段生成多个候选答案并筛选出最优解,有效提升复杂任务的推理效率与准确性。
这一机制特别适用于处理多模态推理场景,例如数学推导、科学问题分析以及复杂场景的视觉理解等。
相比基础模型,LLaVA-o1 在多模态推理基准测试中的性能提升了 8.9%,超越了许多现有的大型模型及闭源对手,展现了其在前沿视觉问答任务中的强大竞争力。
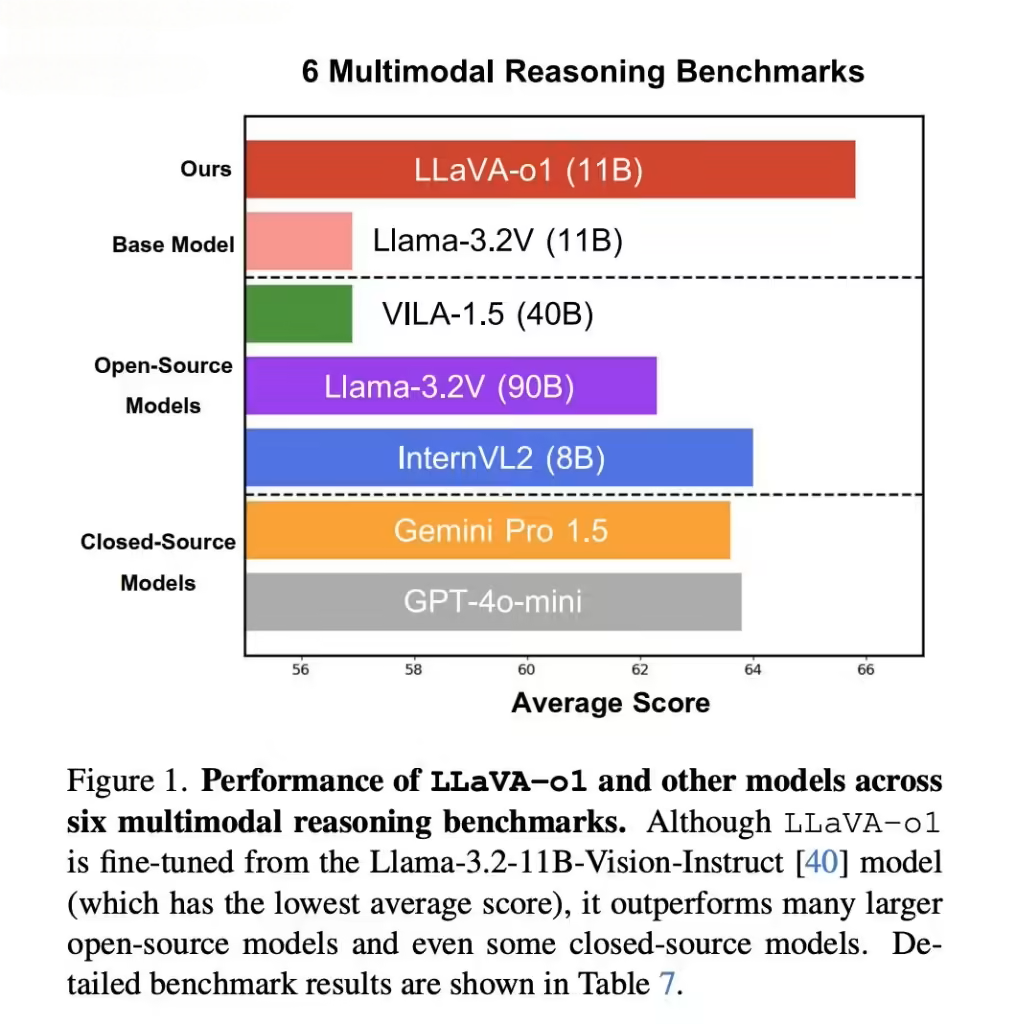
据ITCOW牛新网了解,LLaVA-o1 的推出不仅填补了传统文本与视觉问答模型间的空白,更在数学、科学等需要深度推理的领域表现突出,成为视觉语言领域的重要里程碑。其核心创新在于将结构化推理与视觉处理结合,突破了现有模型在逻辑连贯性和推理能力上的瓶颈。

LLaVA-o1 也是“自发性人工智能”(Spontaneous AI)的重要应用案例。所谓自发性 AI,是指能够模拟动物自发行为的智能系统,通过复杂时间模式和深度学习算法实现更自然的任务响应。这一理念为视觉语言模型提供了新的研究方向,即在增强模型逻辑能力的同时,让其具备更灵活和自然的推理行为。
LLaVA-o1 的推出,为多模态 AI 技术的研究与应用打开了新的可能。未来,随着更多数据资源与优化方法的引入,该模型或将在医疗图像分析、教育辅助工具、自动驾驶场景理解等领域实现更广泛的应用。