ITCOW牛新网 11月28日消息,阿里巴巴通义千问团队今日正式发布实验性研究模型 QwQ-32B-Preview,并配以博文《QwQ: 思忖未知之界》详解其设计理念与性能表现。作为一款专注数学与编程推理的开源大模型,QwQ-32B-Preview 成为全球首个以宽松许可(Apache 2.0)提供的同类领先模型,并在多个基准测试中超越 OpenAI 的 o1-preview 模型。

阿里团队将 QwQ 比喻为“探索未知领域的学徒”,具备在复杂数学、编程推理中的优异表现,尤其在深度逻辑与科学问题的解决上表现突出。其开放性是另一大亮点,作为 Apache 2.0 许可证下的模型,QwQ 可用于商业应用,无需受到诸多开源协议限制。
模型拥有 325 亿参数,支持长达 32000 tokens 的输入提示词,这为长文档理解及复杂任务处理提供了极大便利。
QwQ-32B-Preview 在多个数学与编程领域的基准测试中,展现了其卓越能力:
- MATH-500:该模型在包含500个数学测试样本的评测集上,取得 90.6% 的成绩,远超同类模型,展示出对代数、几何、数论等主题的全面掌握。
- AIME:涵盖中学数学各类主题的评测中,QwQ 得分 50.0%,表现出卓越的数学问题解决能力。
- GPQA:该基准测试模拟科学解题场景,QwQ 评分 65.2%,达到了研究生水平的科学推理能力。
- LiveCodeBench:在评估编程实际问题解决的高难度测试中,QwQ 成绩为 50.0%,验证了其在真实编程场景下的强大生成能力。
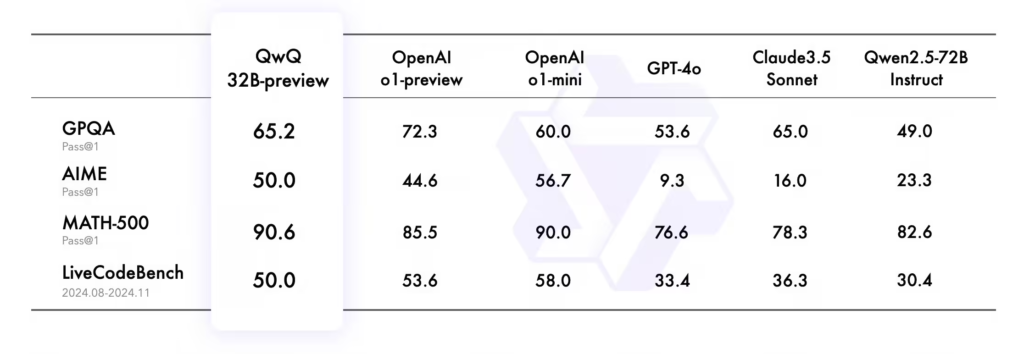
这些数据表明,QwQ 已在推理与解决复杂问题上达到业内顶尖水平,成为少数能与 OpenAI o1 模型正面对抗的开源模型。
尽管 QwQ 具备强大的推理能力,阿里团队在博文中坦承其仍存在以下局限:
- 语言切换问题:回答时可能混用多种语言,影响表达的连贯性。
- 推理循环:在处理复杂逻辑问题时,模型可能陷入递归推理模式,导致回答冗长而不够聚焦。
- 安全性不足:当前安全管控能力有限,可能生成不恰当或存在偏见的回答,生产环境中需谨慎使用并部署额外防护措施。
- 领域能力差异:在数学和编程领域表现卓越,但其他专业领域仍有待优化。
通义千问团队在发布中提到,“思考、质疑、理解,是人类探索未知的永恒追求”。QwQ 的命名和愿景寄托着团队对人类认知边界不断延展的期待。