ITCOW牛新网 12月3日消息,腾讯今日发布混元大模型开源文生视频功能。该模型参数量达130亿,支持中英文双语输入,具备生成高质量、超写实视频的能力,为行业带来全新的生成式AI体验。

腾讯官方介绍,混元视频生成大模型采用DiT架构,配备新一代文本编码器,有效提升语义遵循能力,支持多主体的复杂描绘。模型生成的视频不仅画面高质量、不易变形,还能在光影、镜面反射等场景下实现高度逼真的物理效果。例如:
- 镜面反射同步:在镜面或镜子场景中,反射动作与外部动作完全同步。
- 光影符合物理规律:场景光影的反射和动态变化呈现出自然、真实的视觉效果。



这一能力让用户可以通过简单的文本指令生成细致入微的高质量视频,满足多种应用需求。
腾讯宣布,此次开源包括模型权重、推理代码以及完整的模型算法。企业和个人开发者可以免费使用,并基于模型开发生态插件或应用,推动生成式AI技术的普及与落地。
相关资源获取途径:
- 主页:腾讯混元AI视频生成
- GitHub:HunyuanVideo Repository
- Huggingface:Tencent HunyuanVideo
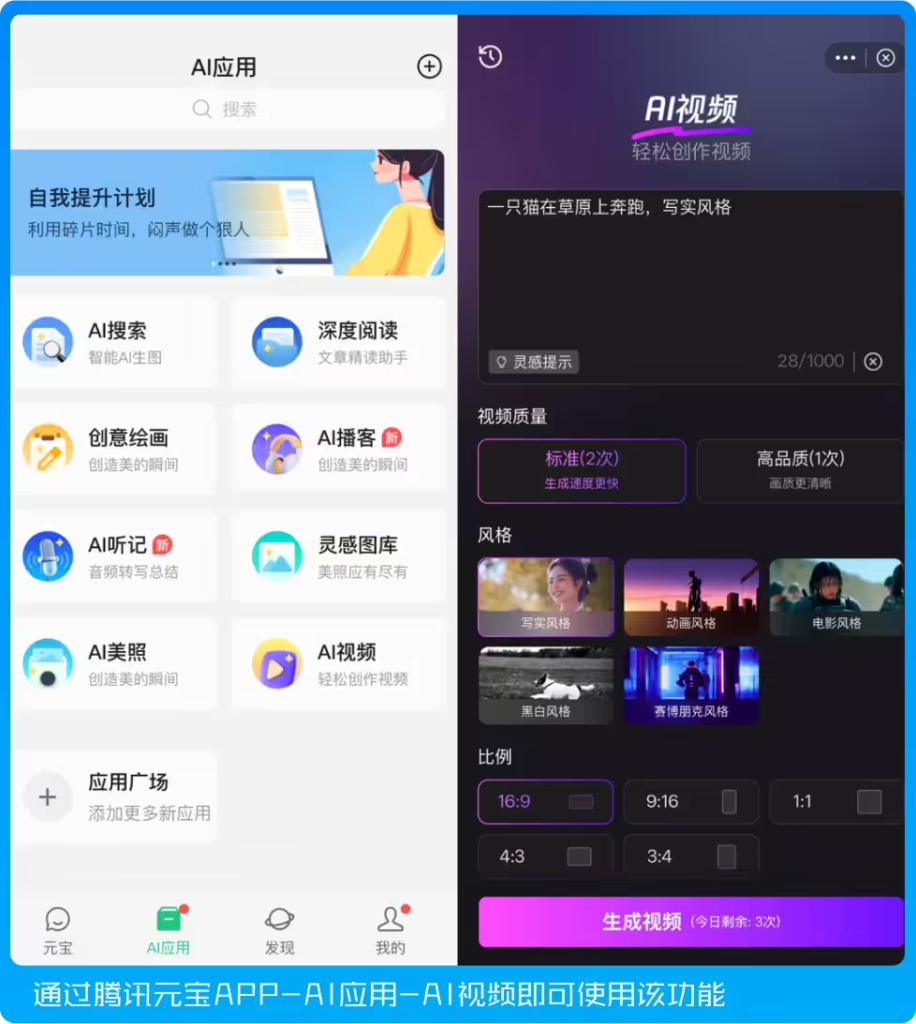
此外,用户可通过“腾讯元宝App”进入“AI应用”模块选择“AI视频”功能,申请试用混元大模型的生成能力。
混元大模型的技术架构采用先进的DiT(Diffusion Transformer)方案,结合优化的文本编码器,有以下显著优势:
- 精准语义遵循:能够深刻理解输入文本的复杂语义,精准映射至视频生成内容。
- 多主体处理:适配多主体场景,支持复杂叙述中的细节表达与动态协调。
- 高保真画质:生成画面精细逼真,减少变形或模糊现象。


混元视频生成大模型的能力适用于多种场景:
- 影视与广告:快速生成特效短片或广告视频,缩短制作周期。
- 教育与培训:制作仿真教学视频,提升学习体验。
- 游戏与虚拟现实:生成动态场景或角色动作,丰富沉浸式体验。