ITCOW牛新网 12月17日消息,谷歌今日正式推出其最强视频生成模型 Veo 2,这款升级版模型在分辨率、时长及对现实世界的理解能力上均取得突破。Veo 2 的推出进一步巩固了谷歌在生成式AI领域的竞争优势,尤其是在视频生成领域,对 OpenAI 的 Sora 模型形成直接挑战。
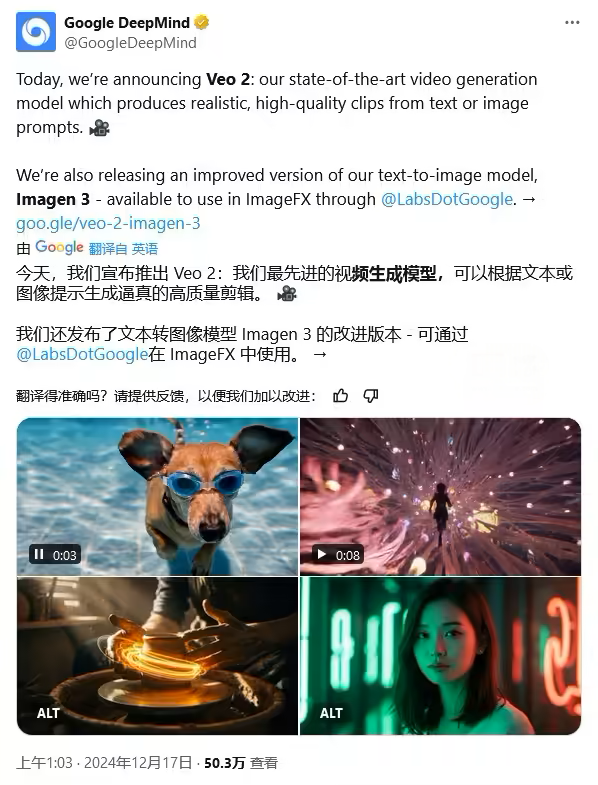
Veo 2 的核心优势与突破
- 最高4K超高清分辨率
Veo 2 模型支持生成 最高 4K 分辨率(4096 x 2160像素) 的视频,这一规格是 OpenAI 的 Sora 模型(最大1080p)的4倍。 - 更长时长,达2分钟
Veo 2 支持生成长达 2分钟 的视频片段,相较于 Sora 的最长20秒,时长提升了6倍,为用户提供了更完整的视觉叙事能力。 - 更深层次的现实理解
Veo 2 加强了对 物理规律、人类运动与细腻表情 的模拟能力,例如流体动力学、光影变化、镜头效果以及电影级表现,生成的视频更加真实且富有动态细节。 - 多模态输入支持
Veo 2 可根据 文本提示 或 文本+参考图像 的组合输入生成高质量视频,满足用户的多样化需求。

目前,Veo 2 仍处于测试阶段,仅在谷歌的实验性工具 VideoFX 中开放使用,但分辨率与时长有所限制:
- 分辨率上限:720p
- 视频时长:8秒
DeepMind 产品副总裁 Eli Collins 表示,未来几个月内,团队将基于用户反馈持续优化和扩展 Veo 2 模型的能力,逐步解锁更高分辨率与更长视频时长。
为应对 AI 视频生成带来的潜在风险,特别是 Deepfake 滥用,Veo 2 集成了专有水印技术 SynthID。该技术通过嵌入隐形标记,使生成的视频内容可被追踪与识别,有效提高内容透明度,减少滥用风险。
Veo 2 的发布标志着谷歌在 AI 视频生成领域的技术跃升,尤其是在分辨率、时长及对现实世界细节的模拟上处于行业领先地位。与 OpenAI 的 Sora 等竞争产品相比,Veo 2 展现了更强的性能与更广的应用潜力。
未来,随着模型迭代和开放程度的提升,Veo 2 有望在影视制作、广告创意、虚拟现实等多个行业掀起变革,为用户提供更加高效、逼真的视觉内容生成工具。