ITCOW牛新网 1月15日消息,月之暗面团队今日发布了全新多模态图片理解模型 moonshot-v1-vision-preview(以下简称“Vision 模型”),进一步完善其 moonshot-v1 模型系列的多模态能力。Vision 模型支持图像识别、文字解析以及多种复杂应用场景。
模型核心能力
1. 图像识别能力
Vision 模型以高精度著称,能够处理图像中复杂的细节与细微差别。官方在演示中展示了模型对一组视觉迷惑图的识别能力:
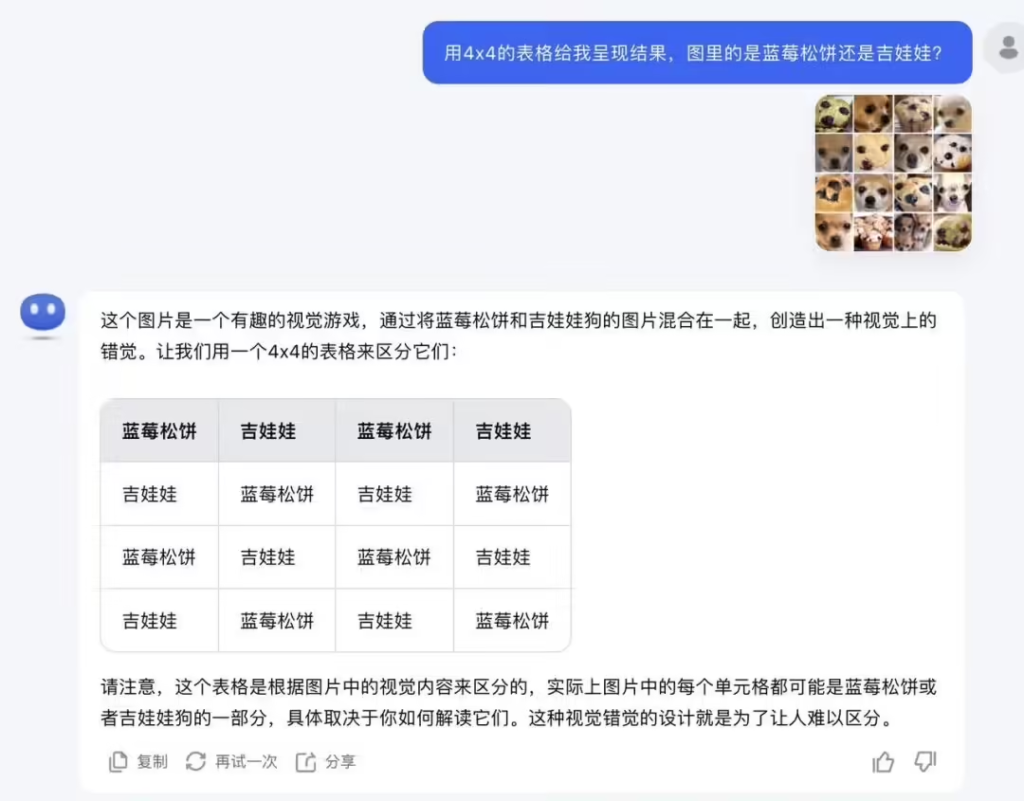
- 蓝莓松饼与吉娃娃识别
在下图示例中,官方通过拼接了16张看似相似的蓝莓松饼与吉娃娃图像,让模型进行逐一识别。Vision 模型成功准确地区分了两者,无论是食物还是动物,都能通过细节差异完成分类。这种能力在食品加工、宠物管理及其他高精度场景中具有广泛应用潜力。
2. 文字识别与理解
Vision 模型还在 OCR 文字识别方面表现出色,不仅可以处理常规打印文字,还能识别手写体内容。例如:
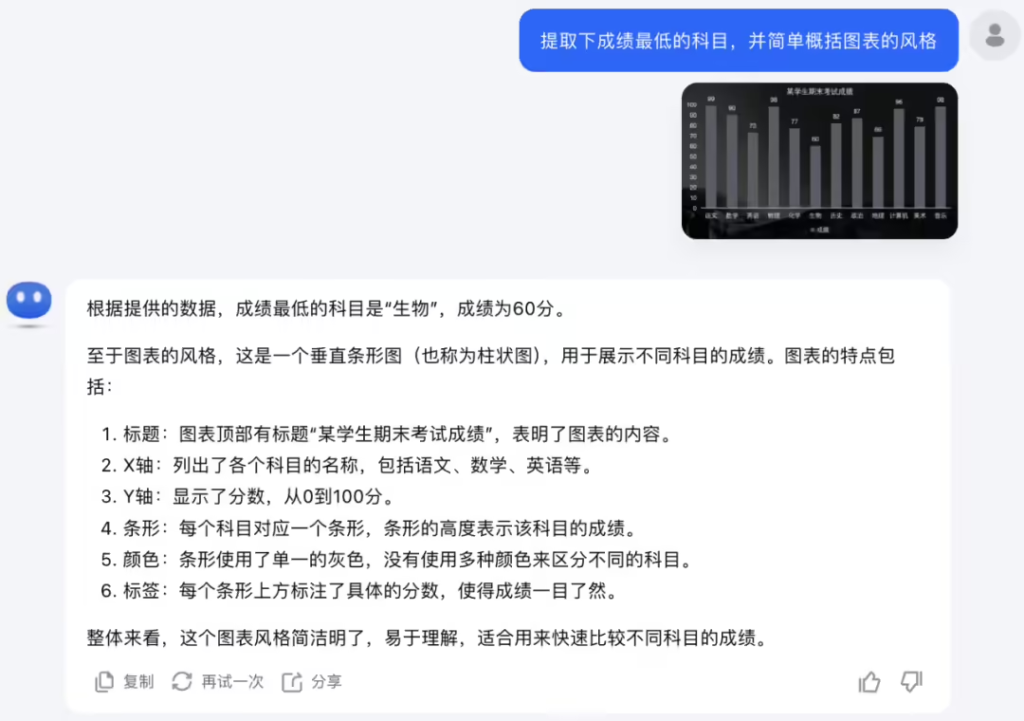
- 收据与手写文本识别
官方展示了模型解析一张手写收据的能力,能够准确提取包括日期、金额、交易单位等关键信息。此外,针对柱状图的分析,Vision 模型不仅能精准读取科目名称及对应的成绩数据,还可以对柱状图的美学风格进行分析,如配色与排版结构。这为文档自动化处理、财务审计和教育评估提供了更强大的支持。

Vision 模型 API 采用 按量计费 模式,根据 token 使用量计算,价格如下:
| 模型版本 | 计费单位 | 价格 |
|---|---|---|
| moonshot-v1-8k-vision-preview | 1M tokens | ¥12.00 |
| moonshot-v1-32k-vision-preview | 1M tokens | ¥24.00 |
| moonshot-v1-128k-vision-preview | 1M tokens | ¥60.00 |
用户可根据具体场景选择适配的模型版本,同时支持 多轮对话、流式输出、工具调用等高级功能,但目前不支持联网搜索或直接通过 URL 加载图片。