ITCOW牛新网 2月23日消息, 近日,OpenAI 的一名员工公开质疑埃隆·马斯克旗下 xAI 公司发布的最新 AI 模型 Grok 3 的基准测试结果,认为其数据具有误导性。对此,xAI 联合创始人伊戈尔·巴布什金(Igor Babushkin)则坚称公司并无不当行为。
xAI 在官方博客发布了一张图表,展示 Grok 3 在 AIME 2025(一个高难度数学考试)中的表现。尽管部分专家质疑 AIME 作为 AI 基准测试的有效性,但它仍被广泛用于评估 AI 数学推理能力。据 ITCOW牛新网了解,xAI 的图表显示,Grok 3 的两个版本——Grok 3 Reasoning Beta 和 Grok 3 mini Reasoning——在 AIME 2025 的得分超过了 OpenAI 目前最强的可用模型 o3-mini-high。
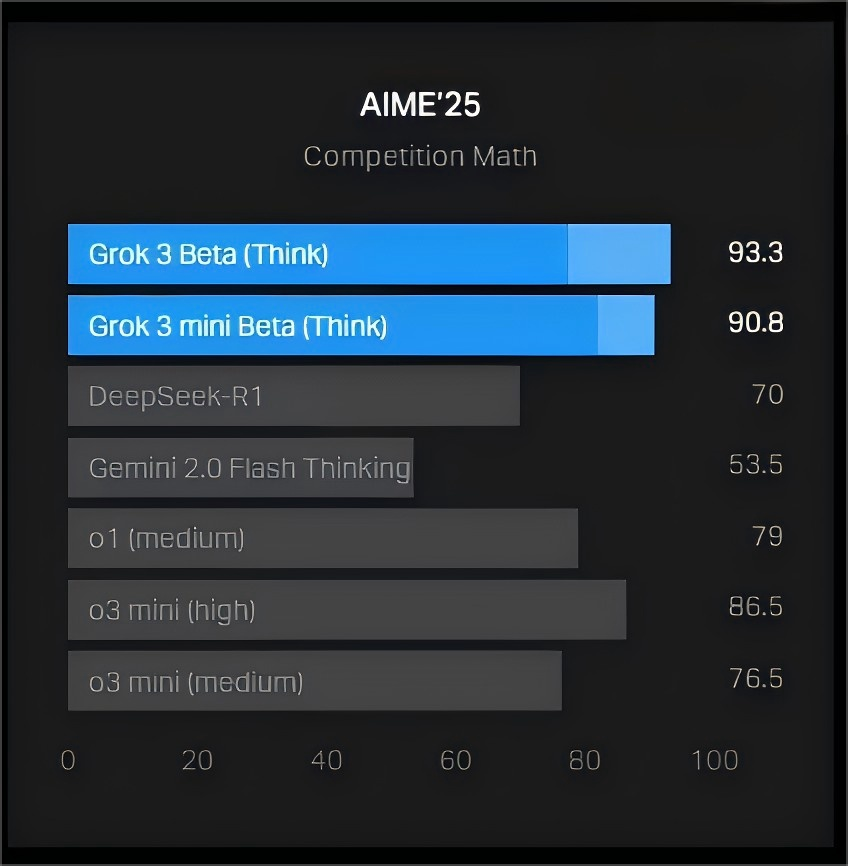
然而,OpenAI 员工在 X 平台指出,xAI 的数据未包含 o3-mini-high 在“cons@64”条件下的得分。“cons@64”指的是“consensus@64”,即允许模型对每道题尝试 64 次,并以最常出现的答案作为最终答案。这种方式通常能显著提高基准测试分数,若省略此数据,可能会让人误以为 Grok 3 在所有条件下都优于 OpenAI 的模型。
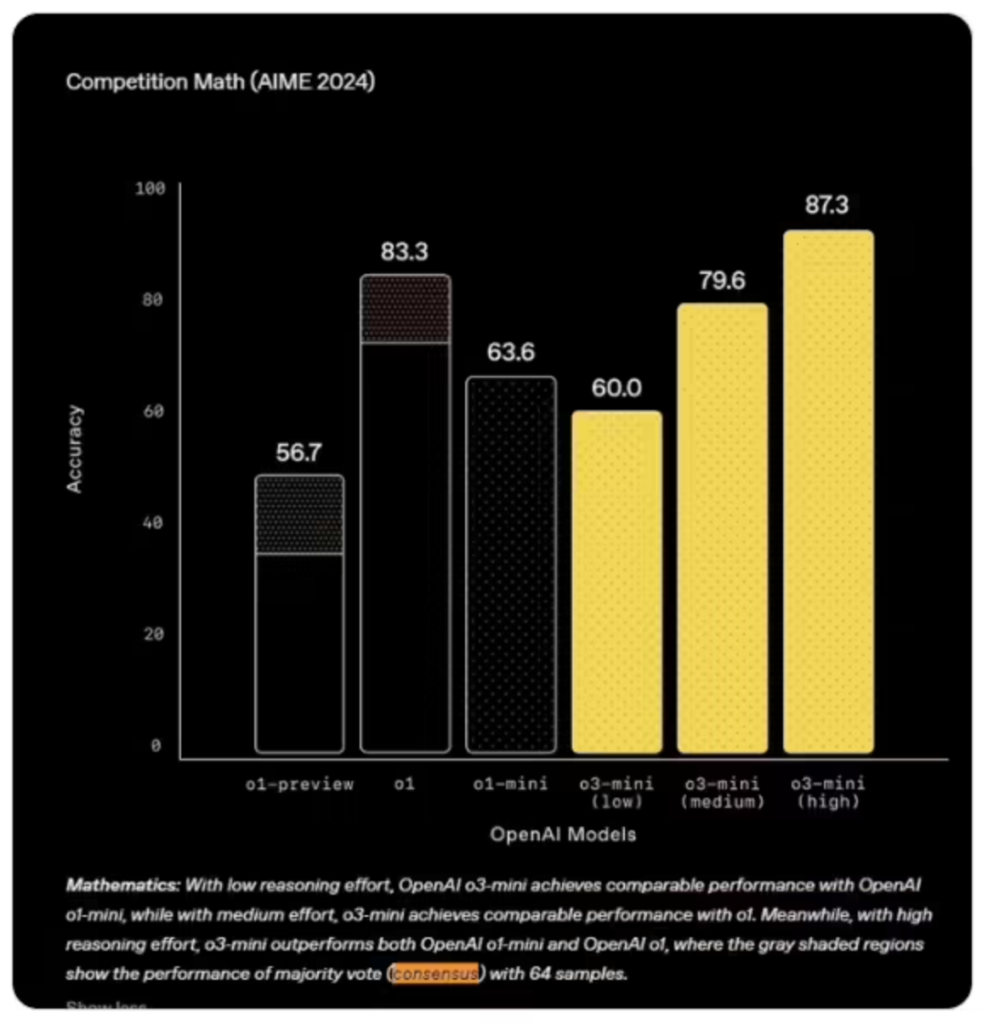
从 AIME 2025 的“@1”测试(模型首次尝试的得分)来看,Grok 3 Reasoning Beta 和 Grok 3 mini Reasoning 皆低于 o3-mini-high。此外,Grok 3 Reasoning Beta 也略低于 OpenAI o1 模型在“中等计算”设置下的得分。但 xAI 依然对外宣称 Grok 3 是“全球最聪明的 AI”。
对此,巴布什金在 X 平台上回应称,OpenAI 过去也曾发布过类似的基准测试图表,只是用于内部模型比较,而非对外竞争。
在这场争议中,一位第三方研究员重新绘制了一张更为“准确”的对比图,以便呈现完整的数据。该对比图表显示,OpenAI 的 o3-mini-high 依然保持领先,在 “@1″ 条件下取得 86.5 分,”cons@64” 提升至 90.8 分。而 xAI 的 Grok 3 Reasoning Beta “@1” 得分 77.3,尽管 “cons@64” 最高提升至 93.3,但缺乏计算和成本优化信息。相比之下,xAI 之前发布的图表省略了 OpenAI 最高得分,可能对比结果有所偏向。此外,其他 AI 模型如 DeepSeek R1、Gemini 1.7 也展现了一定竞争力,但整体仍落后于 OpenAI 和 xAI 旗舰模型。
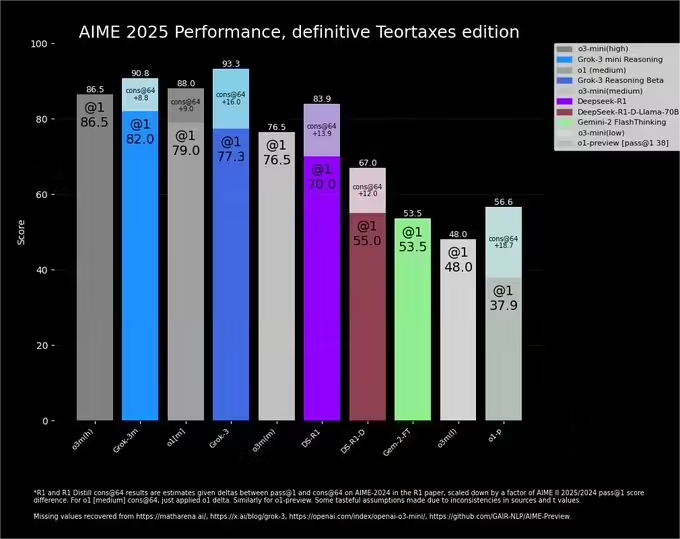
不过,AI 研究员内森·兰伯特(Nathan Lambert)在一篇文章中指出,或许更关键的问题仍未解决——即模型达到最佳得分所需的计算资源和成本。这反映出,大多数 AI 基准测试仍难以全面衡量模型的真实性能和局限性。
此事引发业界广泛关注,也暴露出 AI 评估体系在公平性和透明度上的长期争议。未来,如何构建更客观的 AI 测评体系,可能会成为行业进一步讨论的重点。