ITCOW牛新网 1月17日消息,商汤科技携手上海AI实验室、香港中文大学和复旦大学共同发布了最新一代大语言模型——书生・浦语2.0(InternLM2)。该模型在庞大的2.6万亿token语料库上训练而成,继承了其前身书生・浦语(InternLM)的优良传统,并提供7B和20B两种参数规格以及多种应用场景版本,且将继续以开源形式供公众免费商用。
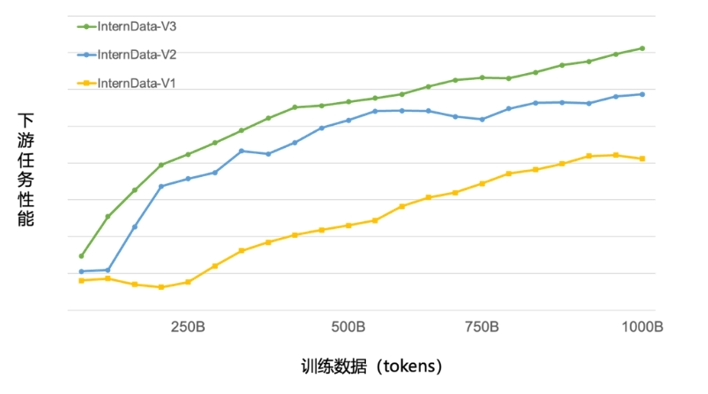
团队在数据清洗过滤技术上取得了显著进展,经过三轮迭代升级,现在仅需使用约60%的训练数据,即可达到原先使用全部数据训练1T tokens的效果。这一突破不仅大幅提升了训练效率,还有助于模型在更广泛的主题和场景中应用。
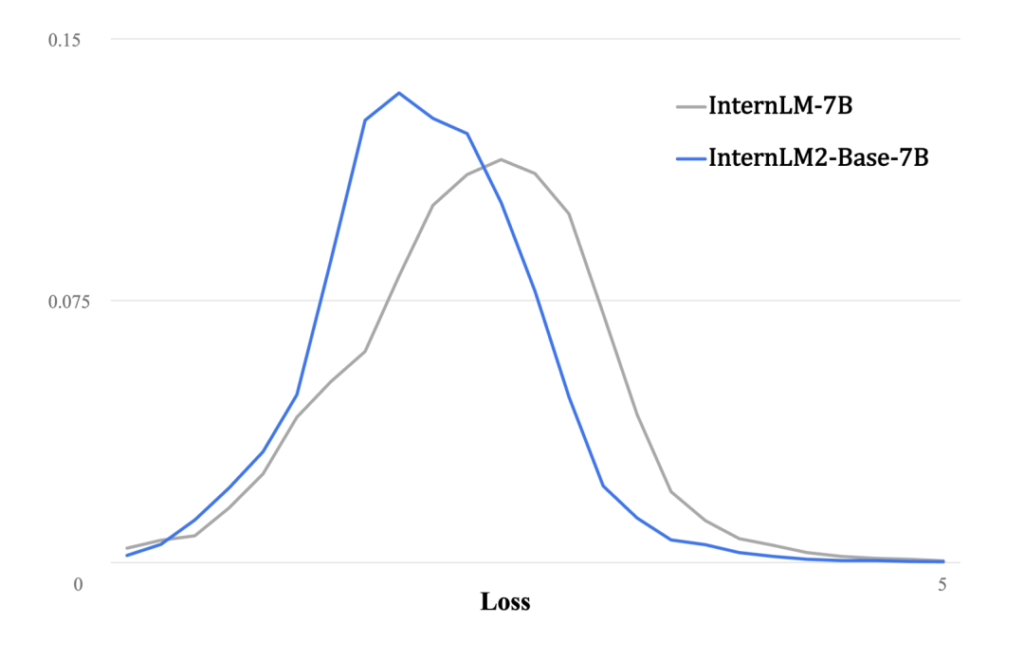
性能评估显示,与第一代InternLM相比,InternLM2在大规模高质量验证语料上的Loss分布呈现出整体左移的趋势,这直接反映了其语言建模能力的实质性增强。此外,通过拓展训练窗口大小和改进位置编码,InternLM2现已能够处理长达20万tokens的上下文,这意味着它可以一次性接收并处理相当于约30万汉字或五六百页文档的内容,极大提升了处理复杂长文本的能力。
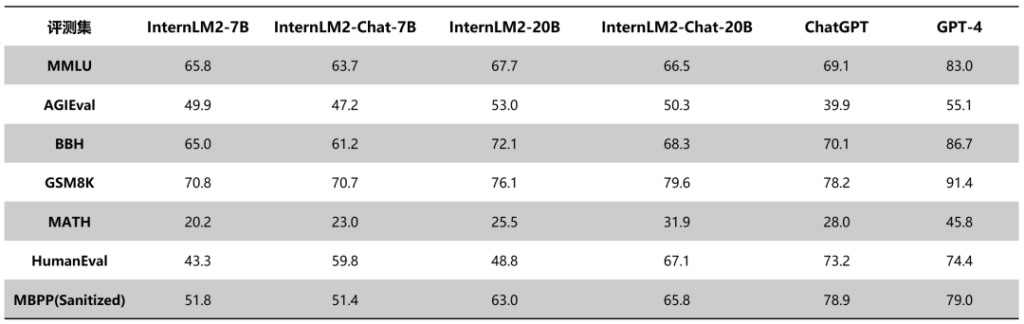
在与当前领先的ChatGPT和GPT-4模型的对比中,InternLM2也展现出了不俗的实力。根据公布的评测数据,在20B参数规模下,InternLM2在多个典型评测集上的表现已接近ChatGPT的水平。
附书生・浦语2.0大模型开源链接如下:
Github:点击访问
HuggingFace:点击访问
ModelScope:点击访问